
Accelerating Sonar Through Speculation

Speculative decoding speeds up the generation speed of Large Language Models (LLMs) by using a quick and small draft model to produce completion candidates that are verified by the larger target model. Under this scheme, instead of a run of the expensive target producing a single token, multiple are emitted in a single step. Here we present the implementation details of various kinds of speculative decoding, applied at Perplexity to reduce inter-token latency on Sonar models.
Speculative Decoding
Speculative Decoding leverages the structure of natural languages and the auto-regressive nature of transformers to speed up token generation. Even though larger models, such as Llama-70B, carry more knowledge than smaller ones, such as Llama-1B, on some simpler tasks they perform similarly. This overlap does suggest that certain sequences are better generated by the less expensive models, leaving complex problems to larger ones. The challenge lies in determining which completions are better and whether the generation of the smaller model is of the same quality as that of the larger one.
Fortunately, LLMs are auto-regressive transformers: when given a sequence of tokens, they output the probability distribution of the next token. Additionally, the logits derived from the intermediate features associated with the tokens in the input sequence also indicate how likely it is for the model to issue those exact tokens. This property enables speculation: if a sequence of tokens is generated by a smaller one starting from an input prefix, it can be run through the larger one to determine how well it lines up with the target model. Each prefix of the candidates is scored with a probability and the longest one above an acceptance threshold is picked. As a bonus, the target model also provides a subsequent token for free: if a draft model generates n tokens, up to n + 1 can be emitted in one step.
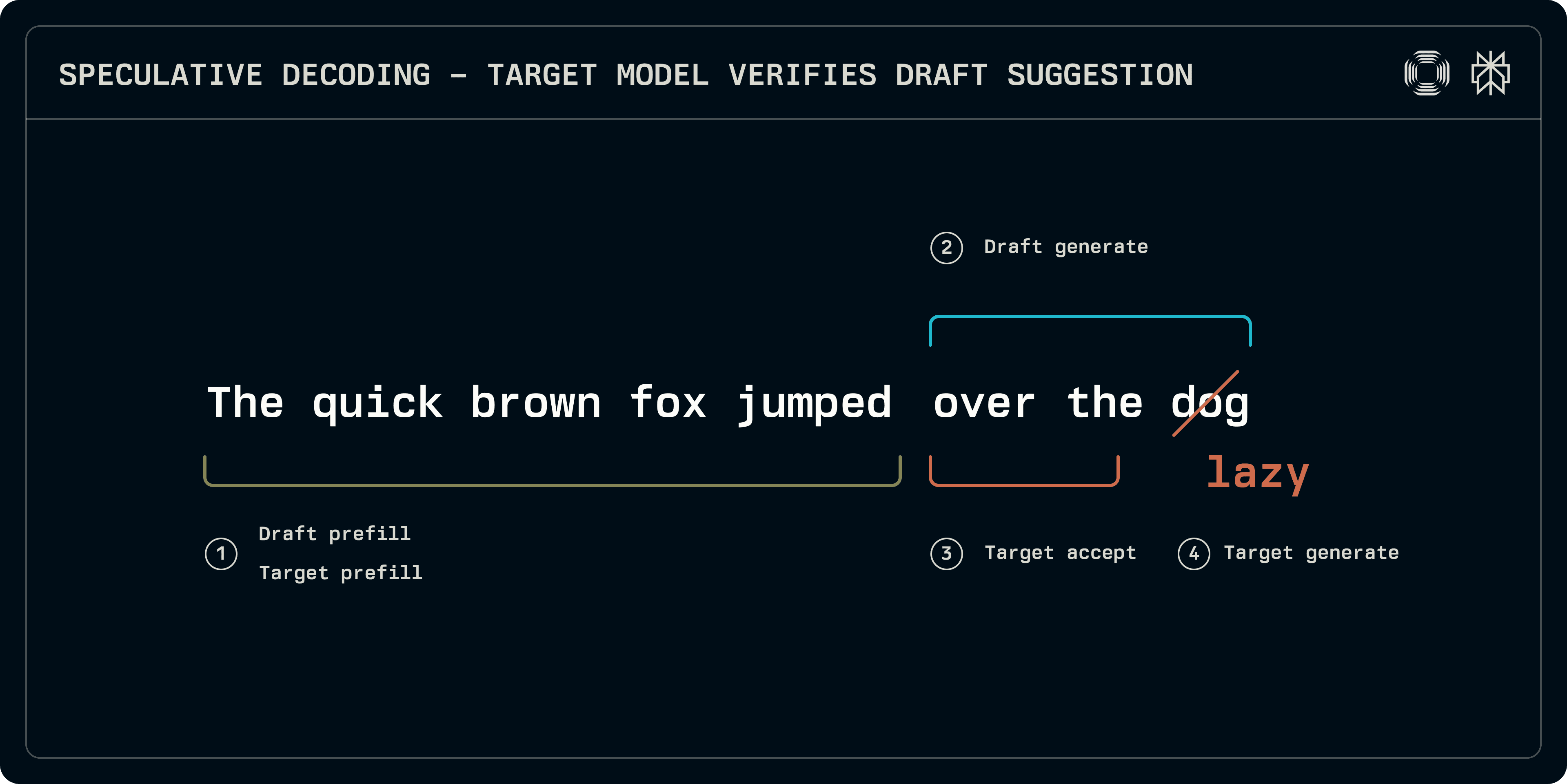
At inference time, speculative sampling process can be split into roughly 4 stages:
Prefill: both the target and the draft models must be run on the input sequence to populate the KV cache entries. While some schemes, such as Medusa, use simpler dense layers for prediction, in this post we focus on transformer-based drafts that need their own KV caches.
Draft generation: the draft model iterates to produce a number of fixed tokens. The draft sequence can be linear or the model can explore a tree-like structure up to a given depth (EAGLE, Medusa). Here, we focus on linear sequences.
Acceptance: the target model runs on the draft sequence, building logits corresponding to each draft token. The length of the longest acceptable sequence is determined.
Target generation: since the target generated logits, at the mismatched position or the tail end of the sequence the logits correspond to a subsequent token. These logits can be sampled to provide a robust token from the target, capping off the sequence.
Various methods exist to implement speculative decoding. In this post, we will focus on the schemes we used to accelerate Sonar models using an in-house 1B model, as well as the prediction mechanisms we are building out to speed up models at the scale of DeepSeek.
Target-Draft
Speculative decoding can be achieved by coupling an existing small LLM as a draft model to a target model to generate candidate sequences. In production, we have accelerated Sonar using a Llama-1B model fine-tuned on the same dataset as the target. While this approach did not require training a draft from scratch, the small model still uses significant KV cache capacity and introduces a slight prefill overhead, increasing TTFT.
Under this scheme, the decoder only speculates on decode-only batches, generating tokens through standard sampling during prefill or on mixed prefill-decode batches. In the prefill stage, the target logits are immediately sampled to also prefill the newly-generated token in the KV cache of the draft. The draft is not sampled yet, but the logits it produces are carried over to the decode stage.
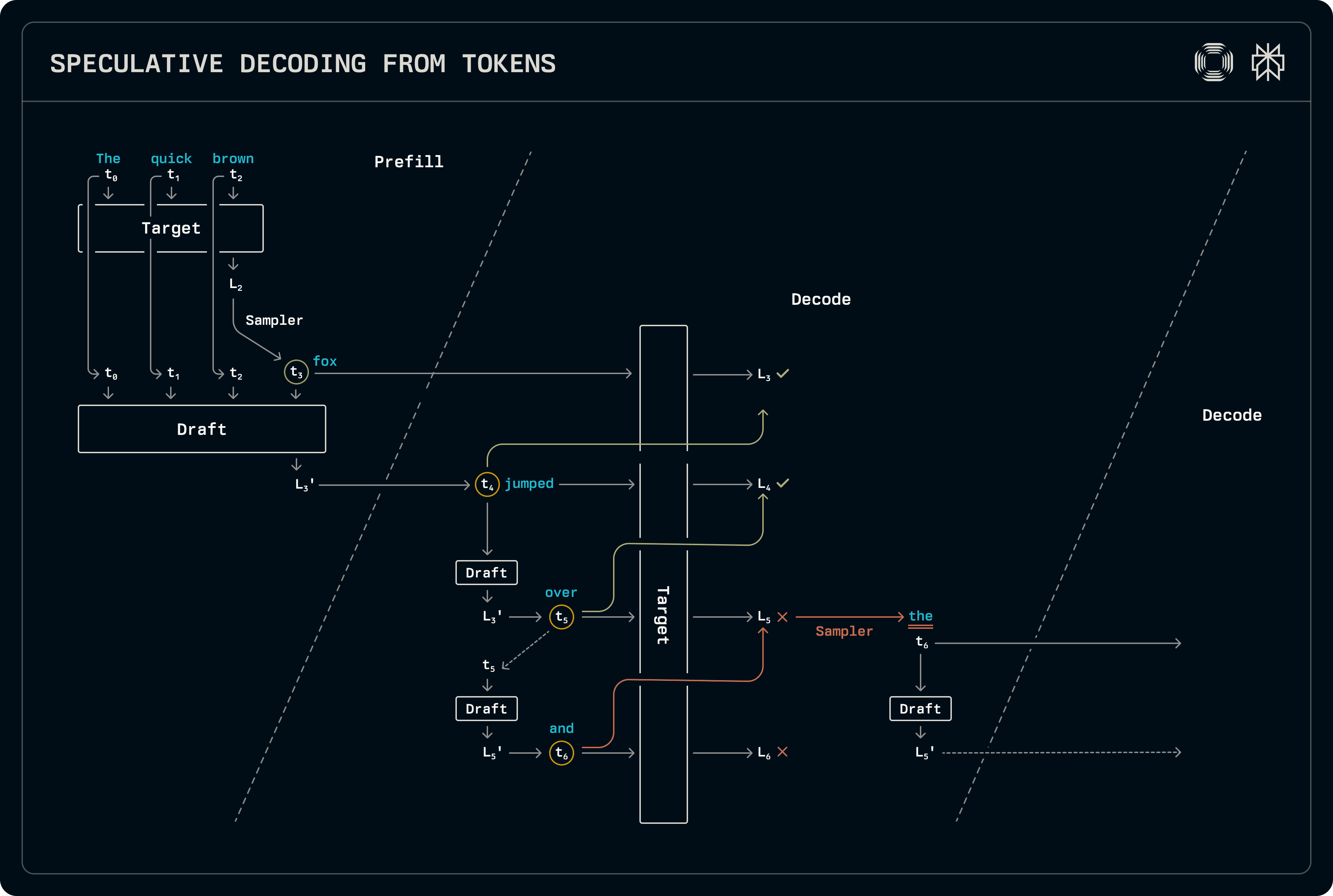
In decode, the draft model is advanced, sampling the top token at each stage. After the desired draft length is reached, the tokens are run through the target model to produce the logits based on which the sampler identifies the accepted sequence length. Acceptance is determined by comparing the full probability distributions from the draft and the target. Since the target always outputs one set of logits following the accepted draft sequence, that is sampled to produce an additional output. Since the draft model has not yet seen that accepted token, it is re-run to populate its corresponding KV cache entries in preparation for the next decode step, carrying the logits over again.
EAGLE
EAGLE is speculative decoding scheme which explores multiple draft sequences, generated through a tree-like traversal of probable draft tokens. A fixed (EAGLE) or dynamically-shaped (EAGLE-2) tree is explored using consecutive executions of the draft tokens, considering the Top-K candidates at each node instead of following the highest scoring token in a linear sequence. The sequences are then scored and the longest suitable one is selected to continue, also appending an additional token from the target.

In order to achieve more accurate prediction, an EAGLE draft model predicts not only based on tokens, but also using the target features (last layer hidden states) of the target model. The disadvantage of EAGLE is the need to train custom, small draft models which are accurate enough to generate suitable candidates within a low latency budget. Typically, a draft model is a single transformer layer identical to a decoder layer of the original model, which is tightly coupled to the target by tying to its embeddings and lm_head projections. Since this requires less KV cache capacity, EAGLE has a lower memory footprint.
To verify tree-like sequences in the target model, custom attention masks must be used. Unfortunately, using a custom attention mask for a whole sequence significantly slows down attention for realistic input lengths (by up to 50%), nullifying some of the speedup achievable through speculation. We have not yet deployed full tree exploration to production for this reason, focusing instead on the special case of single-token prediction via MTP-like schemes presented in the DeepSeek-V3 Technical Report.
MTP
This scheme is similar to draft-target decoding, with the exception of hidden states being used alongside tokens for prediction. Slightly more work must be done in both the prefill and decode stages compared to regular draft-target speculation. The draft model uses both tokens and hidden states: token t_{i+1} is sampled from the logits L_i corresponding to token t_i, which in turn are derived from the hidden states H_i. Consequently, the input token buffers must be shifted one step to the left relative to the hidden state vectors output by the target. The figure below marks the correspondences used for training, as well as the shift during inference.
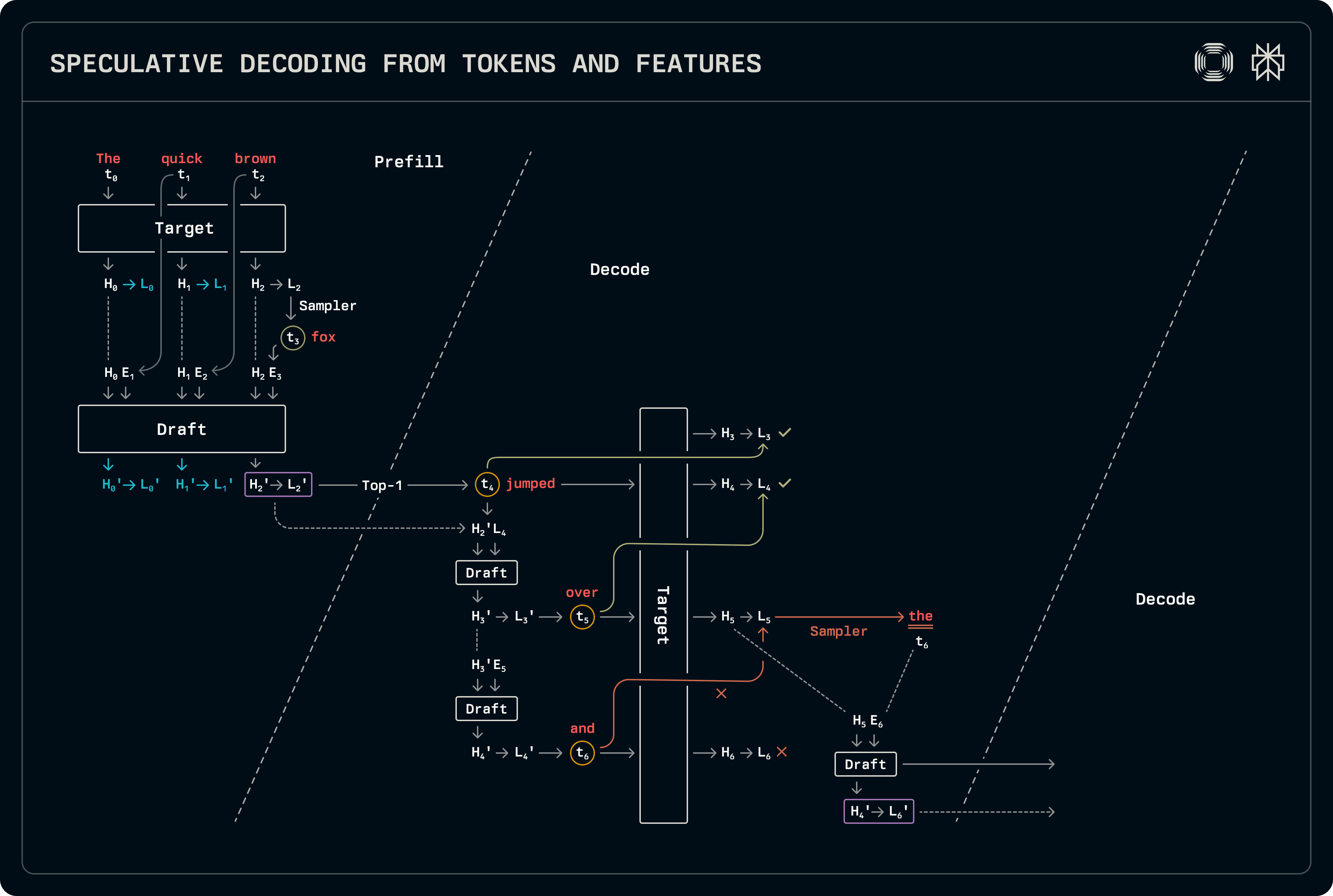
The decoding flow is quite similar to draft-target decoding, with the exception of both hidden states and logits being carried over. Our implementation shares all the associated sampling and logit processing logits, specializing only the model forward invocations. When multiple tokens are predicted, the draft model uses draft hidden states for prediction, also populating KV cache entries based on its own features. In the long run, this can degrade accuracy. Subsequently, when running the draft model to populate the KV cache entry for the target prediction, we run it on the whole sequence taking the more accurate target hidden states as inputs. Since these draft models are small, the added cost of processing the additional tokens is negligible.
Training MTP Heads
In order to benefit from MTP, we built the infrastructure required to train MTP heads attached to our fine-tuned models on Perplexity’s datasets, running on one node with 8xH100 devices. In about one day, we can build heads for models ranging from Llama-1B to Llama-70B and DeepSeek V2-Lite. For larger models, we rely on MTP heads built during the fine-tuning process.
The target of MTP training is to match up the draft hidden states and logits extrapolated from the target hidden states to the next token logits and hidden states of the target. Since inference for hidden states is expensive, we pre-compute them using our inference-optimized implementation of the target model, to be used during training. However, to validate the inference MTP implementation and ensure that numerical differences due to quantization or optimizations do not hinder results, for validation loss and accuracy estimation we fully re-use the inference implementation of both the target and the draft models.
When scaling from the ShareGPT dataset used in the original paper to larger samples, we noticed that the MTP head architecture outlined and implemented in the EAGLE paper failed to train for 70B-sized models. Unlike ShareGPT which contained a larger number of shorter sequences, we train on a slightly smaller number of substantially longer prompts. Since the original EAGLE heads slightly diverged in structure from a typical transformer, we re-introduced some RMS Normalization layers that were stripped. We found that this not only allowed training to converge, but it also boosted the accuracy of the heads by a few percentage points.

Not only do layer norms facilitate training, re-introducing the norms is also mathematically intuitive. MTP heads re-use the embeddings and the logit projections of the target model, as they can be substantial in size (about 2 GB for Llama 70B). During training, these are frozen and the expectation is that the MTP layer learns to embed predictions into the same vector space as what the projection layer of the original model learnt during training. By dropping the norms, a single MLP is expected to learn the same function as an MLP followed by a norm, which hinders the matchup between the hidden states of the draft and the target models.
Inference with Speculative Decoding
In the inference engine, in order to generate tokens for input sequences, they need to be first grouped into reasonably-sized batches, then pages must be allocated in the KV cache for the next tokens. The input tokens and the KV page information is then packed into a buffer broadcast to all parallel ranks running the model. Finally, the metadata is copied into GPU memory and the model is executed to produce the logits from which the next token is sampled.
Unlike certain implementations which loosely couple a draft and target inference server via a wrapper that orchestrates requests between them, our draft-target pairs are tightly coupled and step through generation in unison. Batch scheduling and KV page allocation is shared between the models for all forms of speculative decoding: this unifies the logic that bridges a model with the overarching inference server, as they all expose the same interface.
The inference runtime at Perplexity is shaped around FlashInfer, which determines the metadata that needs to be built in order to configure and schedule the attention kernel. Given some input sequences forming a batch, for prefill, decode or verification, CPU-side work must be done to allocate intermediate buffers and populate certain constant buffers used in attention. This work is in addition to the cost of batch scheduling and KV page allocation, which also incur latencies that must be hidden in order to maximize GPU utilization.
While we fully parallelized CPU-side and GPU-side work for inference without speculation, we found that the CPU-GPU balance for speculative decoding is more intricate. The main challenge arises from the fact that the number of accepted tokens determines the sequence length for a subsequent run, introducing a difficult-to-avoid GPU-to-CPU synchronization point. We experimented with different scheduling schemes in order to best hide the latency of CPU work.
Draft-Target Schedule
Despite being smaller than a target model, when an entire LLM is used as the draft, it still introduces considerable latency on the GPU, providing some headroom to hide expensive CPU operations. Since smaller models do not benefit from tensor parallelism, there is a mismatch between the number of ranks a target and a draft are sharded across. In our implementation, the draft model runs only on the leader rank of a TP group.
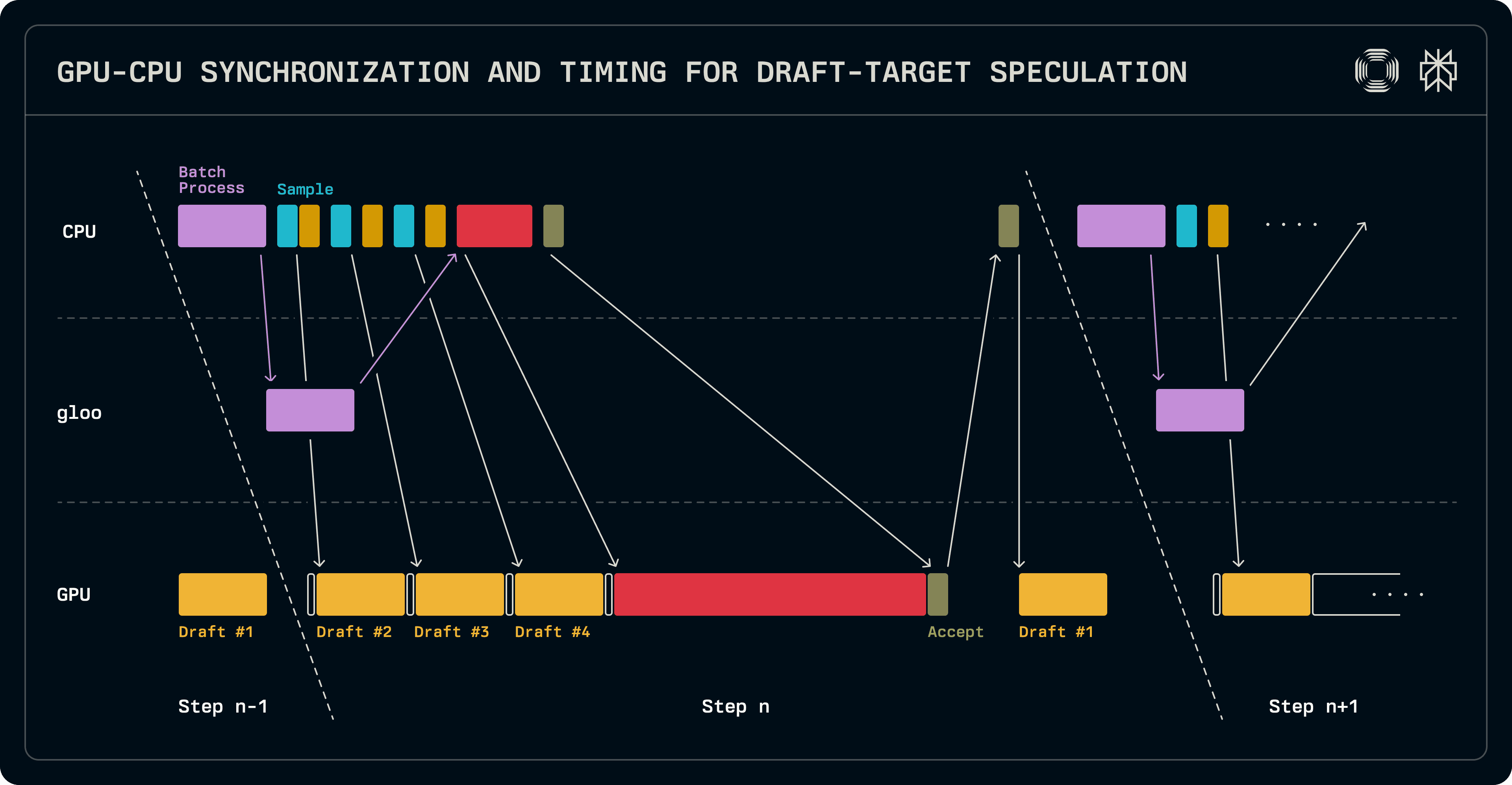
As indicated before, a decode step carries over logits into the next run. This allows us to overlap one execution of the draft model with the CPU-side batch scheduling work. After the batch is put together, repeated calls to the sampler and the draft produce the draft tokens. In parallel, the batch for verification is put together for the target model and synchronized with the parallel workers. The target logits are verified and sampled to determine the accepted sequence lengths. At this point, GPU-to-CPU synchronization is necessary in order to determine subsequent sequence lengths. Since the draft model is only run on the leader node, its batch is set up sequentially and its execution is kicked off to populate its KV cache entries with the additional token that the target produced. The logits produced by this draft run in the current run will be used to sample the first draft token in the subsequent run. Most importantly, while the draft is running, the next batch can be scheduled.
MTP Schedule for a Single Token
While the runtime does not yet provide Eagle-style draft tree exploration, we implemented a special case of this scheme, considering a linear sequence of draft tokens produced by a model the size of a single transformer decoder layer. This scheme can be used for draft prediction using the open-source weights of DeepSeek R1. The sub-case of predicting a single token is interesting, as large MTP layers achieve sufficiently high acceptance rates to justify their overhead.
MTP scheduling is somewhat more complex, as the draft model is much faster, hiding less CPU-side latency. Additionally, the draft is sharded alongside the target model, requiring shared memory transfers for batch information. A run starts by transferring batch info and sampling the first token from carry-over logits, similarly to the previous scheme. Next, the target is run to validate tokens, processing 2 * D tokens, where D is the decode batch size. This is ideal for micro-batching in Mixture-of-Experts (MoE) models over slower interconnects such as InfiniBand, as the batch splits evenly into two halves. The hidden states of the target carry over to the next draft run, while the logits are passed into the sampler for verification.

By performing a limited amount of additional work on the GPU, we avoid CPU-to-GPU synchronization after draft sequence acceptance. After the input tokens of the targets are shifted, a kernel plugs in the next target tokens into their corresponding locations. The draft is then re-run with the same batch information as the target, populating KV cache entries and building the logits and hidden states for the next run, doing some redundant work on tokens which were not accepted. In these situations, the latency of the unused work is barely measurable due to the small size of the draft model. In parallel with the draft run, sequence lengths are determined on the CPU and the scheduling of the next batch is kicked off, without having to wait for GPU work to terminate.
The overhead of additional work in the draft layer is not noticeable in attention, however MLP layers are more problematic. Since matrix multiplication instructions pad to a boundary of 64 along the dimension of number of tokens, if doubling doesn’t require significantly more blocks, the overhead is hidden. For longer draft sequences the overhead is more expensive and the scheme used for regular draft-target models works better.
References
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving