
High-Performance GPU Memory Transfer on AWS Sagemaker Hyperpod

Journey to 3200 Gbps: High-Performance GPU Memory Transfer on AWS Sagemaker Hyperpod
Modern deep learning infrastructure often requires transferring large amounts of data between GPUs across machines. At Perplexity, we encountered a unique technical challenge: efficiently transferring non-contiguous GPU memory regions between machines at maximum possible speed. Our target platform, AWS p5 instances, offers an impressive 3200 Gbps of network bandwidth through 32 network cards. This article shares our journey of building a custom high-performance networking solution that achieves 97.1% of this theoretical bandwidth.
The Technical Challenge
Our use case presented several key technical requirements:
High-bandwidth transfer between remote GPUs of non-contiguous memory chunks
Ability to dynamically add or remove nodes from Kubernetes deployments without disrupting ongoing operations
Support for peer-to-peer communication patterns
While NVIDIA's NCCL library is the de facto standard for distributed deep learning, it wasn't ideal for our use case:
NCCL excels at collective communication but requires establishing a static "world", which requires restarting the entire cluster when adjusting the participating nodes.
NCCL's synchronous communication model adds complexity for our asynchronous workload
We wanted direct control over our memory transfer patterns for optimization
Building our own solution provided valuable learning opportunities
Modern High-Performance Networks
To understand our solution, let's first explore how modern high-performance networks differ from traditional networking.
Most networks we use daily rely on TCP/IP protocols, where applications communicate with the network card through the operating system kernel using sockets. However, high-performance networks use RDMA (Remote Direct Memory Access) - a completely different hardware and software stack that enables direct memory access between machines without involving the CPU.
AWS provides Elastic Fabric Adapter (EFA), a custom network interface that implements Amazon's custom protocol called Scalable Reliable Datagram (SRD). Unlike traditional TCP/IP networking where data must be copied multiple times between user space, kernel space, and network buffers, EFA with RDMA allows direct data transfer between GPU memory and the network card, bypassing the CPU entirely.
Philosophy of High-Performance Network Design
Building high-performance networking systems requires rethinking several fundamental assumptions:
Buffer Ownership: Unlike traditional sockets where the kernel manages network buffers and requires copying between user space and kernel space, RDMA requires applications to manage their own buffers. When an application initiates a network operation, it transfers buffer ownership to the network card until the operation completes, eliminating the need for data copying.
Memory Registration: Applications must register memory regions with the operating system kernel. The kernel sets up virtual address mappings that allow the CPU, GPUs, and network cards to all understand the same virtual addresses. This registration is a one-time operation that enables subsequent zero-copy data transfers.
Control Plane vs Data Plane: High-performance networks separate operations into two categories:
Control plane operations (like connection setup and memory registration) go through the kernel to ensure security
Data plane operations (actual data transfer) bypass the kernel for maximum performance
Reception Before Transmission: Without kernel-managed buffers, applications must pre-post receive operations, specifying where incoming data should be placed. This is a fundamental shift from the socket model where applications can receive data at any time.
Poll-based Completion: Instead of waiting for kernel notifications through mechanisms like
epoll, applications directly poll hardware completion queues. This eliminates system call overhead and allows immediate reaction to completed operations.Hardware Topology Awareness: Understanding and optimizing for hardware topology is crucial for achieving maximum performance.
Understanding Hardware Topology
AWS p5 instances have a sophisticated internal architecture. As shown below, each instance contains two CPU sockets forming two NUMA nodes, with each NUMA node connecting to four PCIe switches:
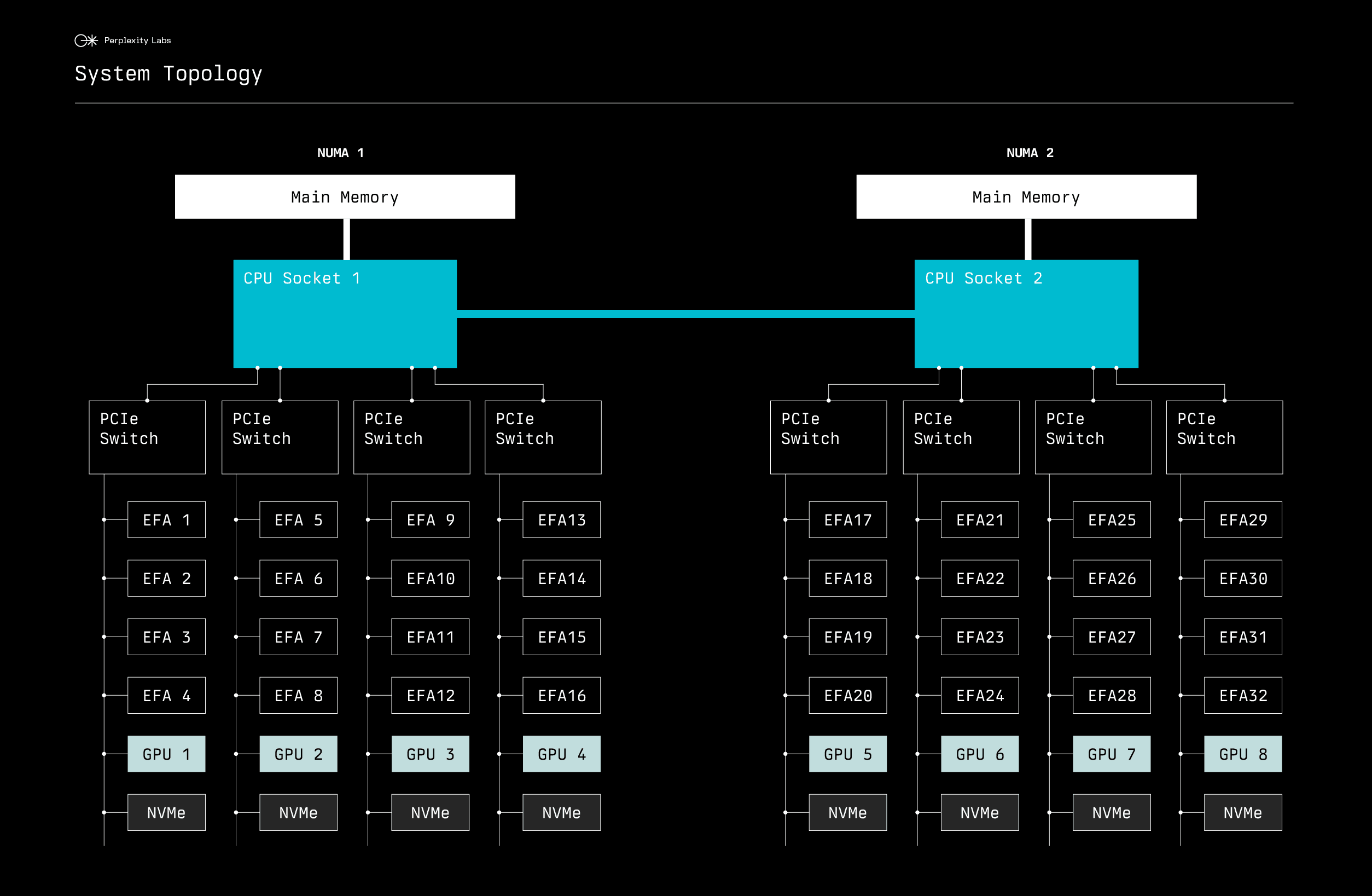
Under each PCIe switch, we find:
Four 100 Gbps EFA network cards
One NVIDIA H100 GPU
One NVMe SSD
The data paths for TCP/IP and RDMA transfers demonstrate fundamental differences in their approaches:
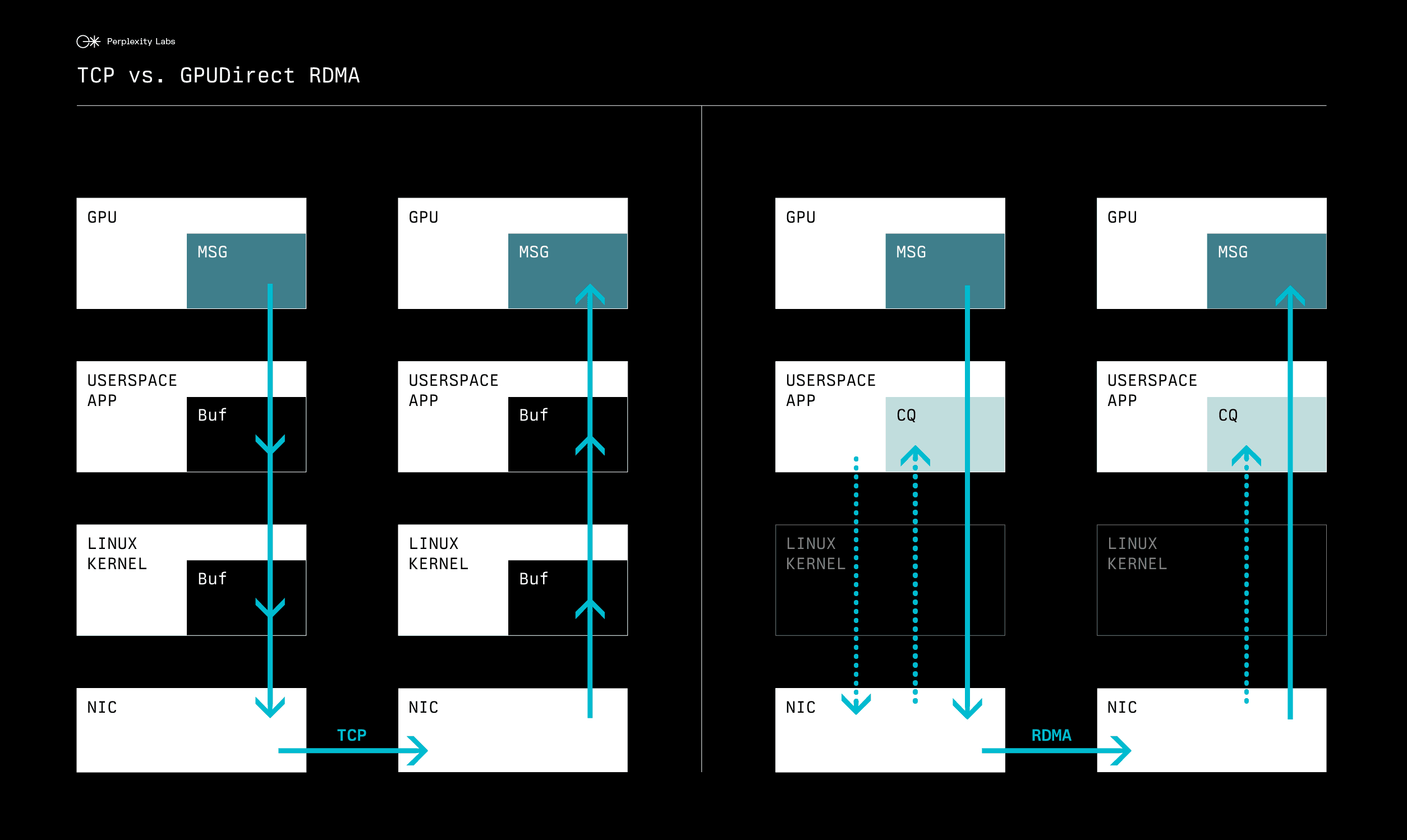
With TCP/IP (left side), data must be copied multiple times:
From GPU memory to application buffer in user space
From user space buffer to kernel buffer
From kernel buffer to network card
Reverse process happens on the receiving side
Each copy operation consumes CPU cycles and memory bandwidth. The application must also context switch between user space and kernel space for each network operation.
In contrast, RDMA (right side) provides true zero-copy data transfer:
The network card reads directly from GPU memory
Data travels directly to the remote network card
Remote network card writes directly to the destination GPU memory
The application only needs to check a completion queue (CQ) in user space to know when the transfer is done
With RDMA and proper hardware pairing, transferring data between two GPUs only requires traversing the local PCIe switch and the network:
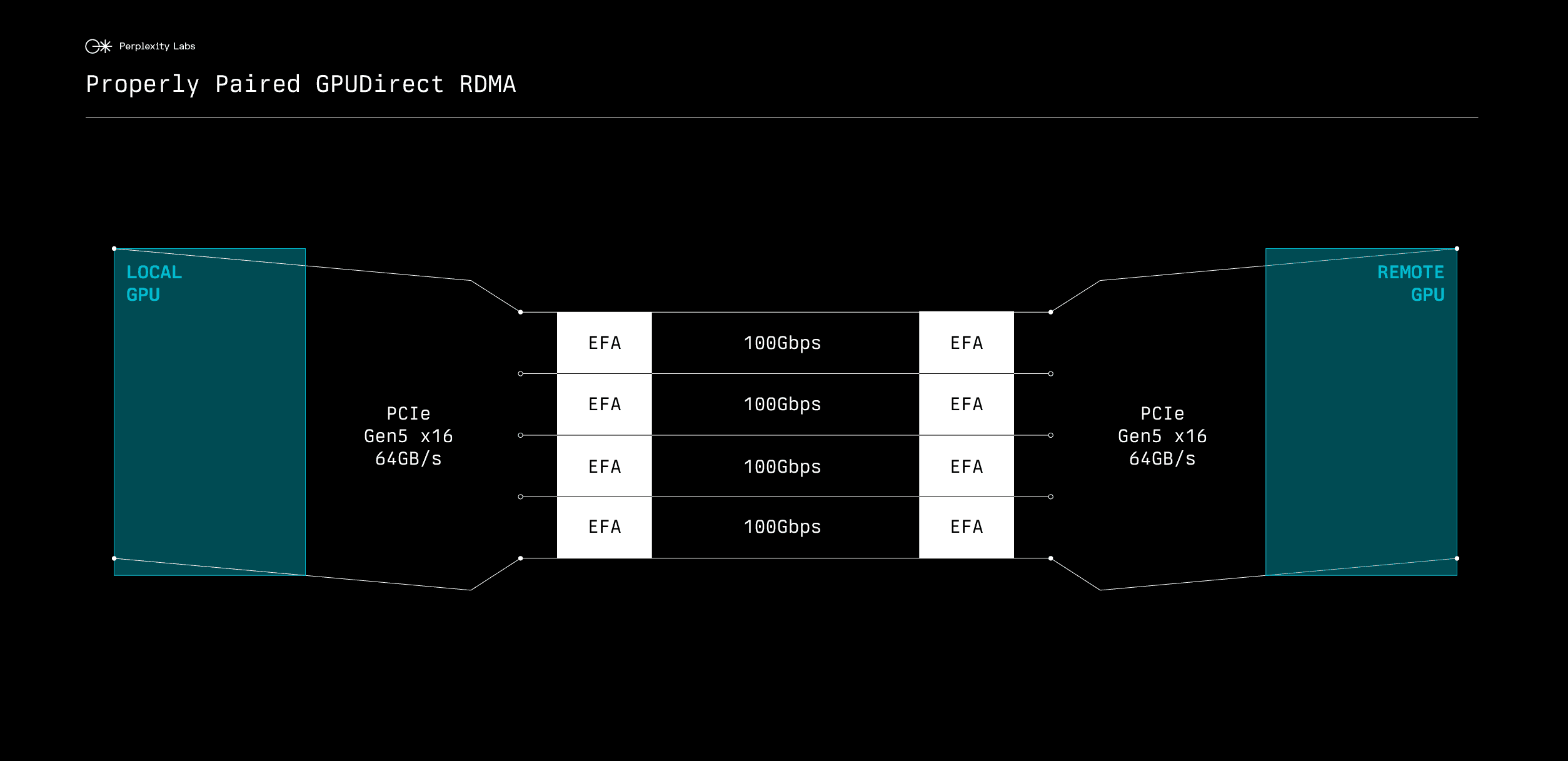
In contrast, TCP/IP transfers must copy data multiple times through main memory, causing significant PCIe bus congestion:
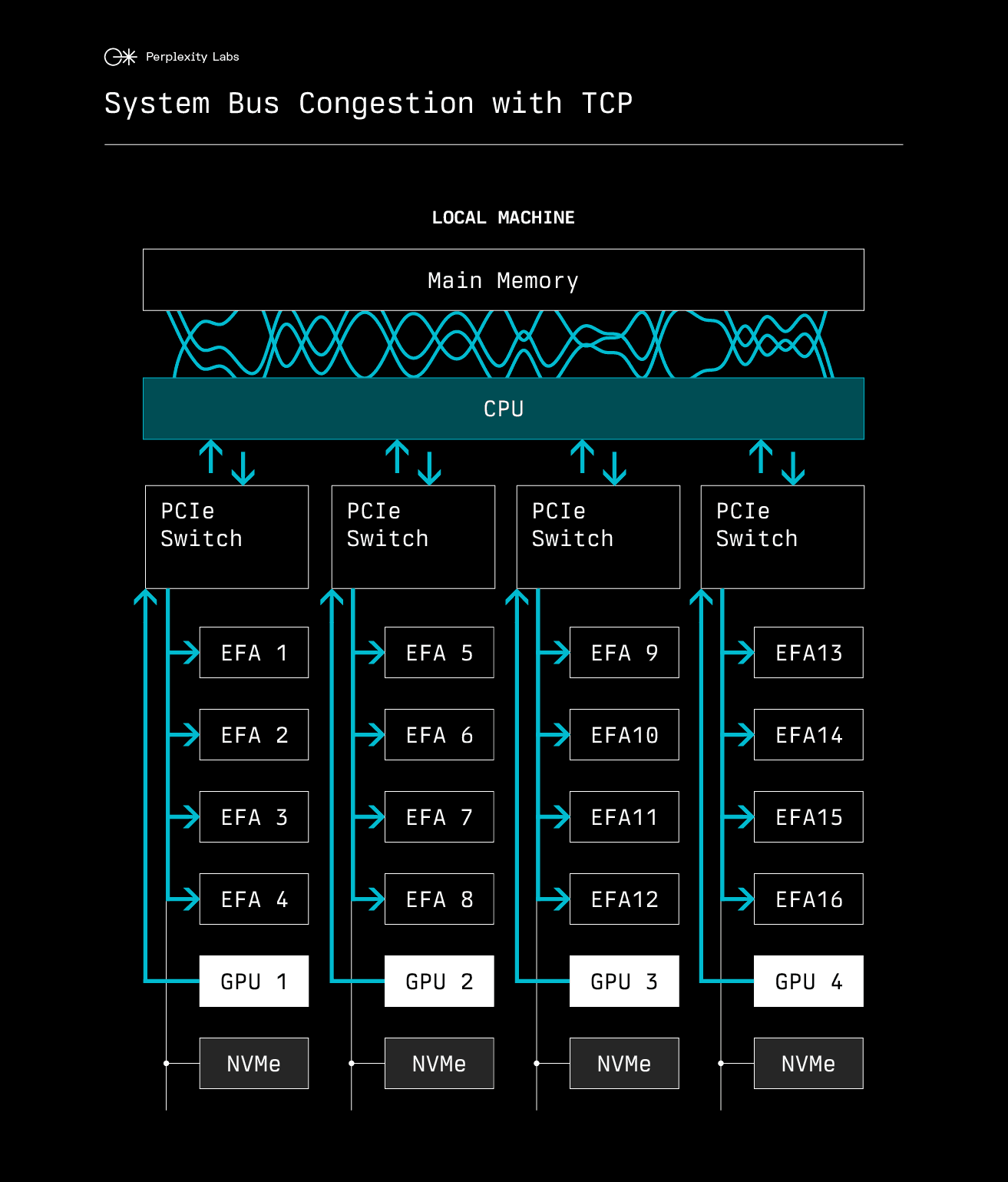
Building with libfabric
We used libfabric - a framework that provides a generic interface for fabric services. Our implementation uses two types of RDMA operations:
Two-sided RDMA (SEND/RECV) for control messages that carry metadata about memory regions (e.g., offsets and sizes).
One-sided RDMA WRITE for actual data transfer, where each WRITE operation handles one contiguous memory chunk.
Journey to Peak Performance
Our development progressed through several stages:
Implemented basic unidirectional message transfer using SEND/RECV
Extended to bidirectional communication
Added GPUDirect RDMA WRITE for direct GPU-GPU transfer
Expanded to handle multiple concurrent transfers
Introduced operation queuing for robustness
Achieved 97.4% bandwidth utilization on a single network card
When scaling to 32 network cards, we implemented several crucial optimizations:
Operation Queuing: Rather than directly submitting operations to network cards, we maintain an application-level queue. This provides robustness against network congestion and simplifies the programming model.
Network Warmup: Pre-establishing connections improved startup performance.
Multi-threading: Dedicated threads for each GPU's network operations.
CPU Core Pinning: Binding threads to specific CPU cores to avoid NUMA effects and cache misses.
State Sharding: Reducing contention between threads.
Operation Batching: Submitting multiple operations together.
Lazy Operation Posting: Operations are first queued in the application. After polling the completion queue, we attempt to submit pending operations to the network card, ensuring efficient use of network resources.
NUMA-aware Resource Allocation: Allocate libfabric resources like completion queues on the correct NUMA node to minimize memory access latency.
Through these optimizations, we achieved a final performance of 3,108 Gbps - 97.1% of the theoretical maximum bandwidth.
The video below shows our command-line program in action. It transfers non-contiguous chunks of GPU memory to a remote node, achieving a transmission speed of 3108.283 Gbps - demonstrating near-theoretical bandwidth utilization of the network infrastructure:
Conclusion
Building a high-performance networking system requires understanding both hardware architecture and system design principles. While libraries like NCCL provide excellent solutions for common patterns, sometimes custom solutions are necessary for specific requirements.
Our journey demonstrates that achieving near-theoretical network performance is possible with careful attention to system architecture, hardware topology, and various optimization techniques. The key is not just understanding individual components, but how they interact to form a complete system.
The full technical deep-dive of this journey, including implementation details and code examples, is available in our open source repository.