
Introducing pplx-api

Please note: The below have been deprecated for current models. Learn more about our APIs
We’re excited to announce pplx-api, designed to be one of the fastest ways to access Mistral 7B, Llama2 13B, Code Llama 34B, Llama2 70B, replit-code-v1.5-3b models. pplx-api makes it easy for developers to integrate cutting-edge open-source LLMs into their projects.
Our pplx-api provides:
Ease of use: developers can use state-of-the-art open-source models off-the-shelf and get started within minutes with a familiar REST API.
Blazing fast inference: our thoughtfully designed inference system is efficient and achieves up to 2.9x lower latency than Replicate and 3.1x lower latency than Anyscale.
Battle tested infrastructure: pplx-api is proven to be reliable, serving production-level traffic in both our Perplexity answer engine and our Labs playground.
One-stop shop for open-source LLMs: our team is dedicated to adding new open-source models as they arrive. For example, we added Llama and Mistral models within a few hours of launch without pre-release access.
pplx-api is in public beta and is free for users with a Perplexity Pro subscription.
Use pplx-api for a casual weekend hackathon or as a commercial solution to build new and innovative products. We hope to learn how people can build cool and innovative products with our API through this release. Please reach out to api@perplexity.ai if you have a business use case for pplx-api. We would love to hear from you!
Benefits of pplx-api
Ease of Use
LLM deployment and inference require significant infrastructure undertaking to make model serving performant and cost-efficient. Developers can use our API out-of-the-box, without deep knowledge of C++/CUDA or access to GPUs, while still enjoying the state-of-the-art performance. Our LLM inference also abstracts the complexity and necessity of managing your own hardware, further adding to your ease of use.
Blazing Fast Inference
Perplexity’s LLM API is carefully designed and optimized for fast inference. To achieve this, we built a proprietary LLM inference infrastructure around NVIDIA’s TensortRT-LLM that is served on A100 GPUs provided by AWS. Learn more in the Overview of pplx-api Infrastructure section. As a result, pplx-api is one of the fastest Llama and Mistral APIs commercially available.
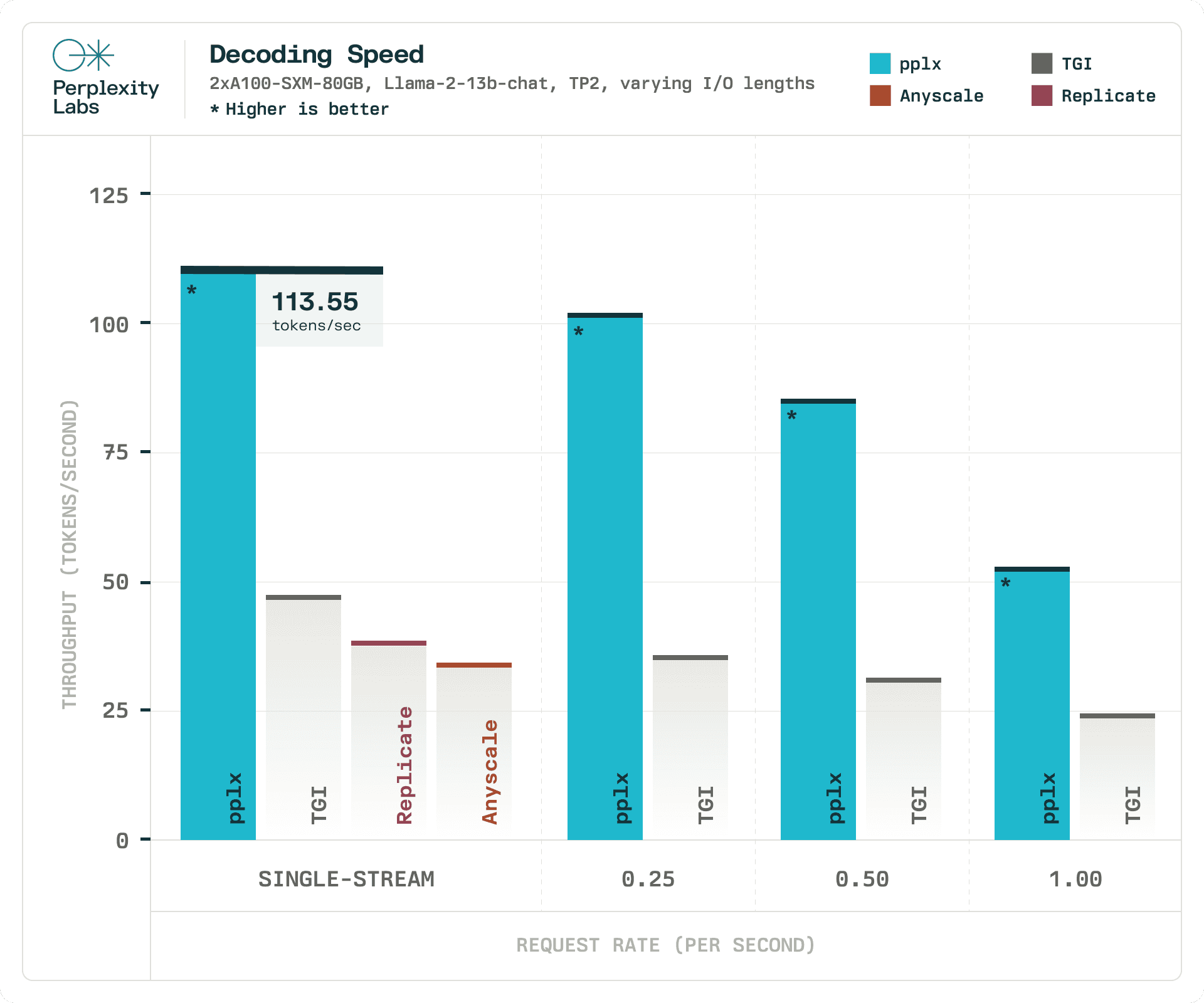
To benchmark against existing solutions, we compared the latency of pplx-api with other LLM inference libraries. In our experiments, pplx-api achieves up to 2.92x faster overall latency compared to Text Generation Inference (TGI), and up to 4.35x faster initial response latency. For this experiment, we compared TGI and Perplexity’s inference for single-stream and server scenarios on 2 A100 GPUs using a Llama-2-13B-chat model sharded across both GPUs. For the single-stream scenario, the server processes one request after another. In the server scenario, the client sends requests according to a Poisson distribution with varying request rates to emulate a varying load. For the request rate, we perform a small sweep up to a maximum of 1 request / second, the maximum throughput sustained by TGI. We used real-world data with a variety of input and output token lengths to simulate production behavior. The requests average ~700 input tokens and ~550 output tokens.
Using the same inputs and sending a single stream of requests, we also measured the mean latencies of Replicate’s and Anyscale’s APIs for this same model to gather a performance baseline against other existing APIs.

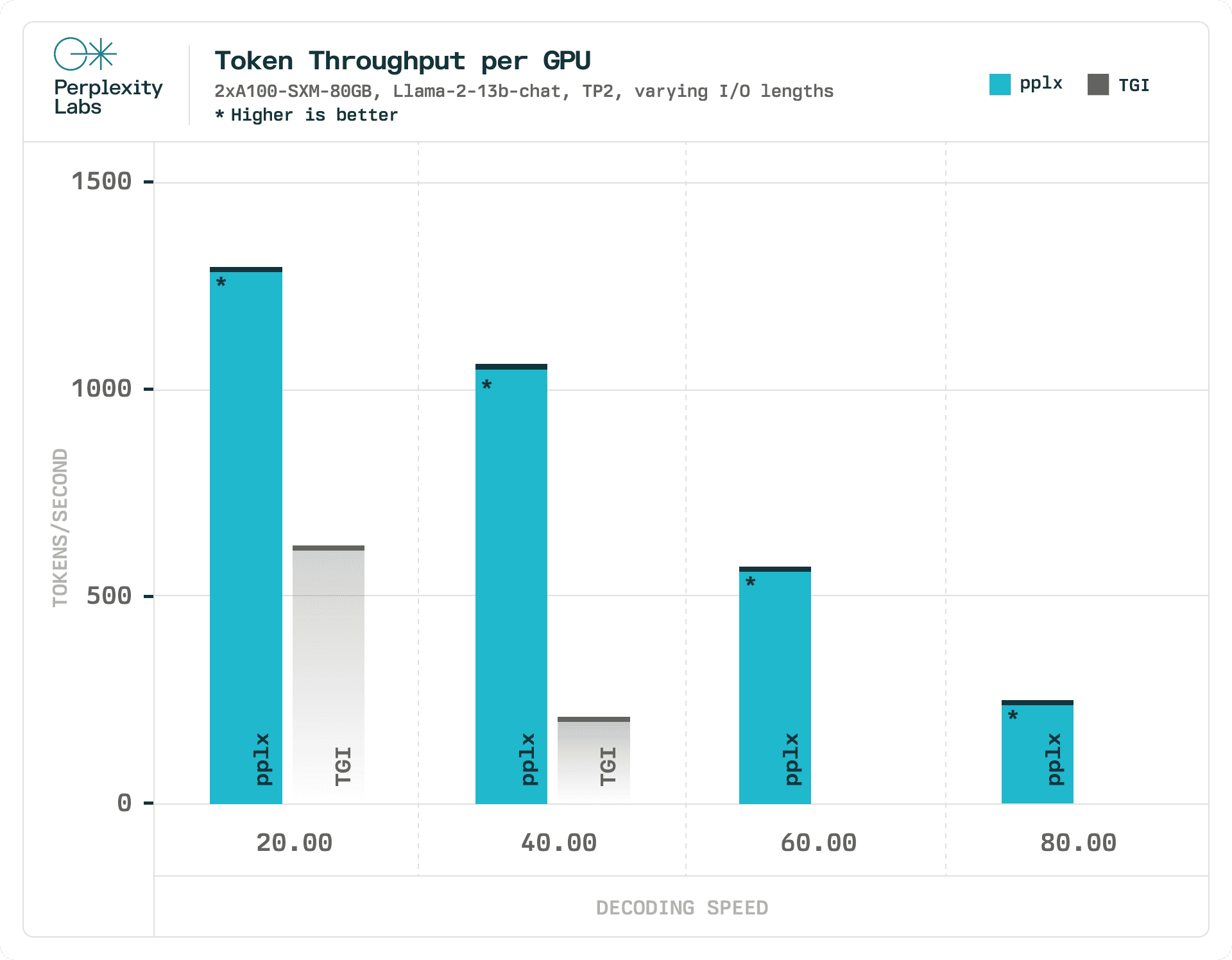
Using the same experimental setup, we compared the maximum throughput of pplx-api against TGI, with decoding speed as a latency constraint. In our experiments, pplx-api processes tokens 1.90x-6.75x faster than TGI, and TGI entirely fails to satisfy our stricter latency constraints at 60 and 80 tokens/second. We evaluate TGI under the same hardware and load conditions that we used to evaluate pplx-api. Comparing this metric with Replicate and Anyscale is not possible since we cannot control their hardware and load factors.
For reference, the average human reading speed is 5 tokens/seconds, meaning pplx-api is able to serve at a rate faster than one can read.
Overview of pplx-api infrastructure
Achieving these latency numbers requires a combination of state-of-the-art software and hardware.
AWS p4d instances powered by NVIDIA A100 GPUs set the stage as the most cost-effective and reliable option for scaling out GPUs with best-in-class clock speeds.
For software to take advantage of this hardware, we run NVIDIA’s TensorRT-LLM, an open-source library that accelerates and optimizes LLM inference. TensorRT-LLM wraps TensorRT’s deep learning compiler and includes the latest optimized kernels made for cutting-edge implementations of FlashAttention and masked multi-head attention (MHA) for the context and generation phases of LLM model execution.
From here, the backbone of AWS and its robust integration with Kubernetes empower us to scale elastically beyond hundreds of GPUs and minimize downtime and network overhead.
Use Case: Our API in Production
pplx-api In Perplexity: Cost Reduction and Reliability
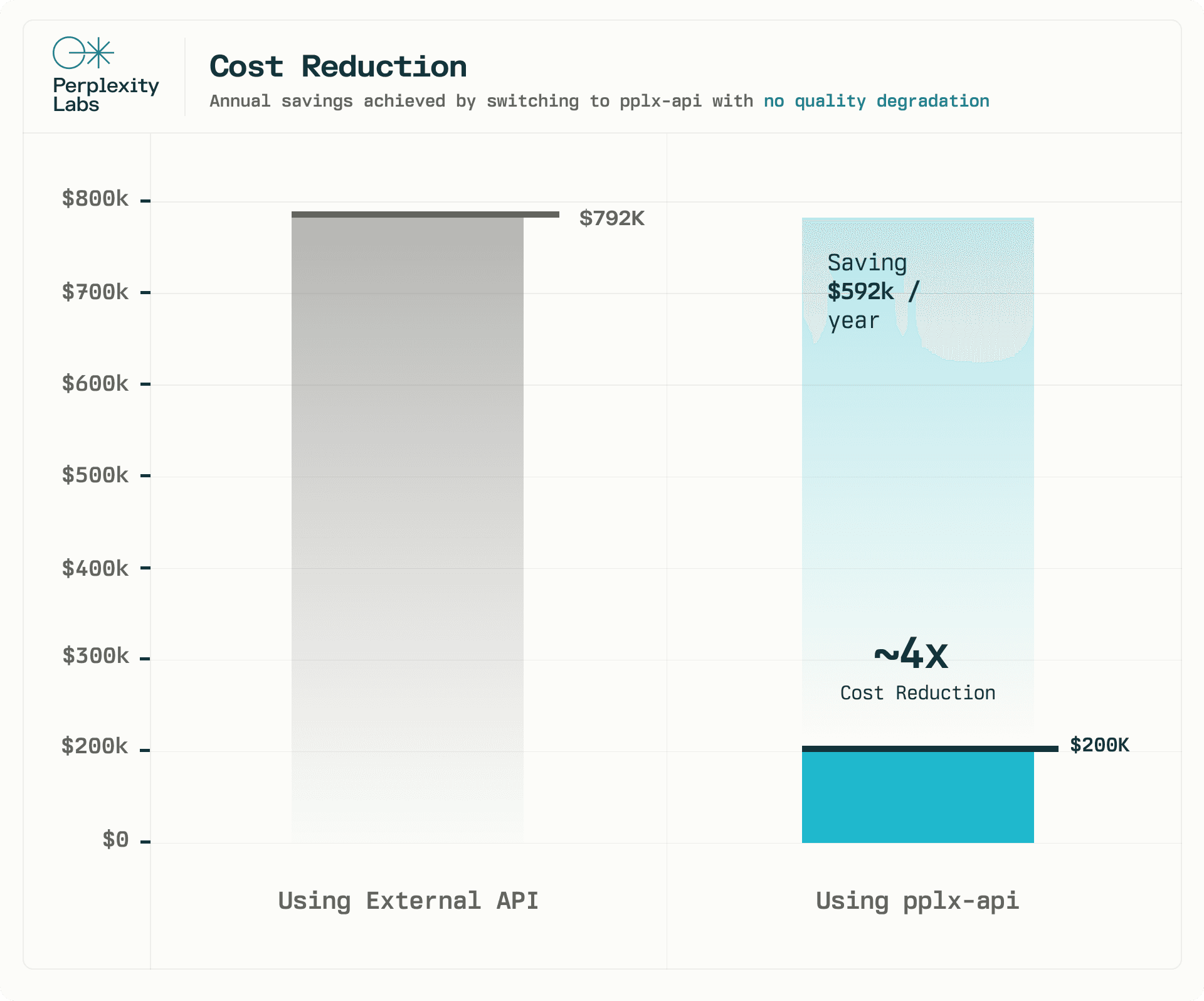
Our API is already powering one of Perplexity’s core product features. Just switching a single feature from an external API to pplx-api resulted in cost savings of $0.62M/year, approximately a 4x reduction in costs. We ran A/B tests and monitored infrastructure metrics to ensure no quality degradation. Over the course of 2 weeks, we observed no statistically significant difference in the A/B test. Additionally, pplx-api could sustain a daily load of over one million requests, totaling almost one billion processed tokens daily.
The results of this initial exploration are very encouraging, and we anticipate pplx-api to power more of our product features over time.
pplx-api in Perplexity Labs: Open Source Inference Ecosystem
We also use pplx-api to power Perplexity Labs, our model playground serving various open-source models.
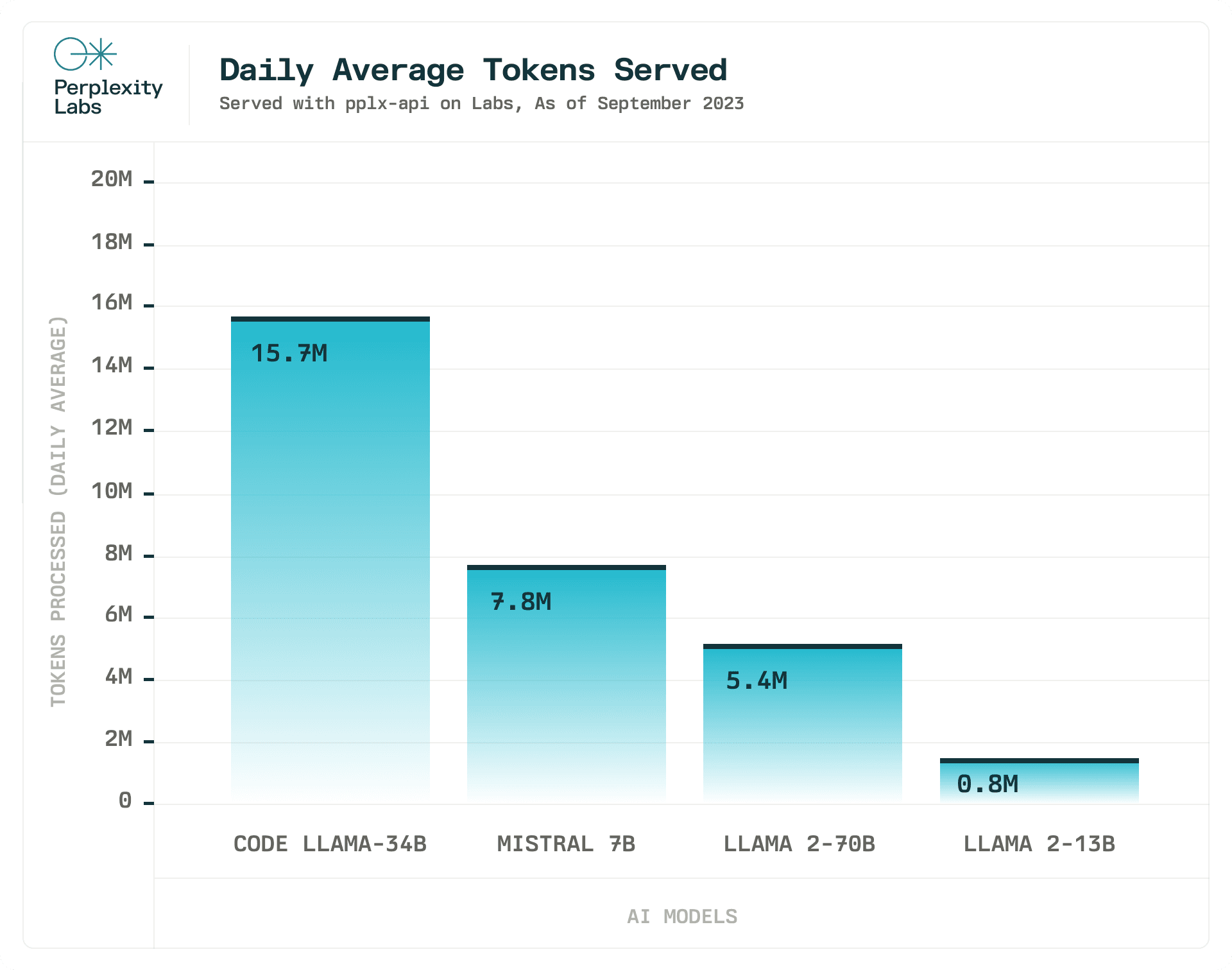
Our team is committed to providing access to the latest state-of-the-art open-sourced LLMs. We integrated Mistral 7B, Code Llama 34b, and all Llama 2 models in a matter of hours after their release, and plan to do so as more capable and open-source LLMs become available.
Get Started with Perplexity’s AI API
You can access the pplx-api REST API using HTTPS requests. Authenticating into pplx-api involves the following steps:
Generate an API key through the Perplexity Account Settings Page. The API key is a long-lived access token that can be used until it is manually refreshed or deleted.
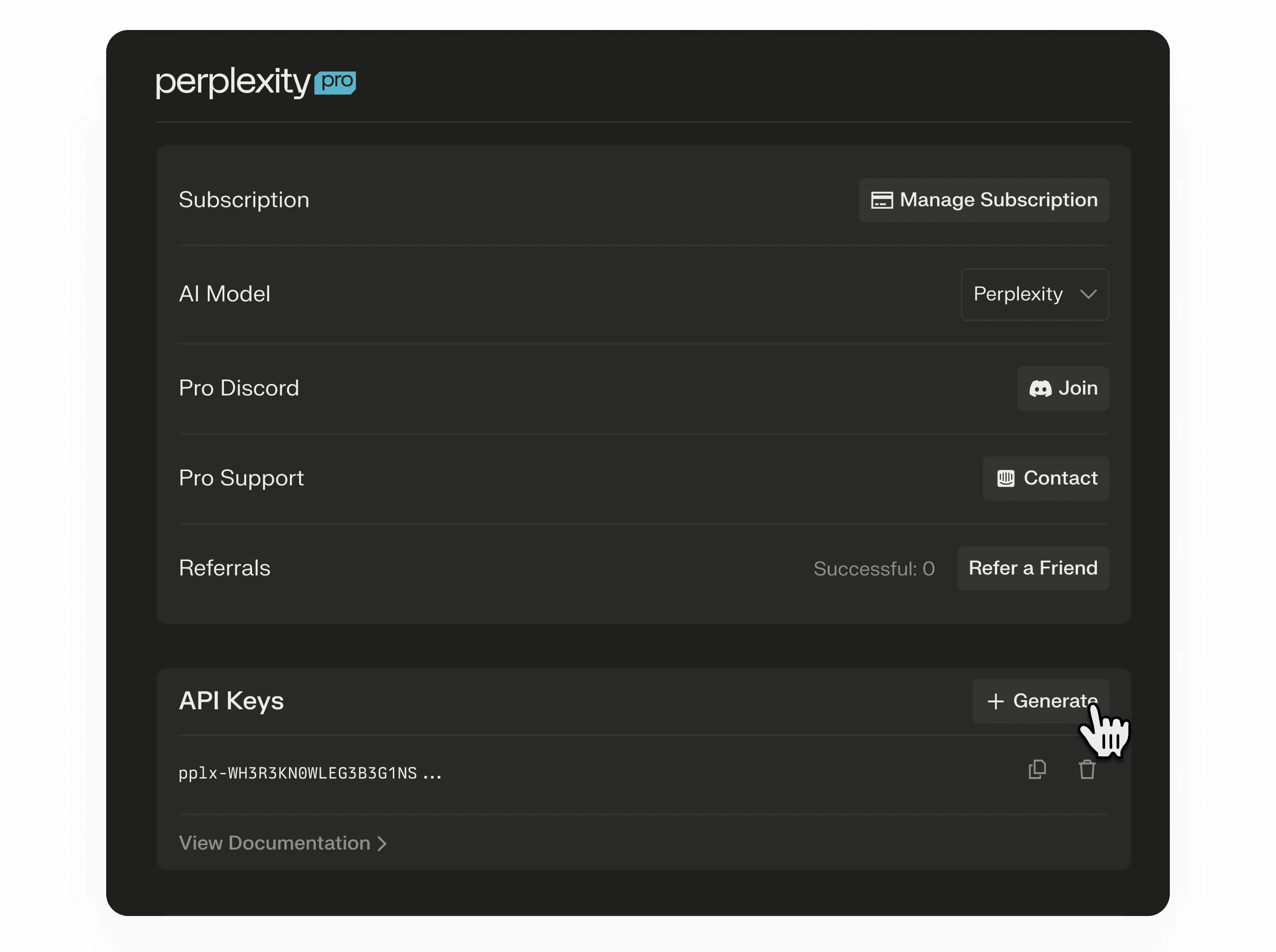
Send the API key as a bearer token in the
Authorizationheader with each pplx-api request.
In the following example, PERPLEXITY_API_KEY is an environment variable bound to a key generated using the above instructions. CURL is used to submit a chat completion request.
curl -X POST \ --url https://api.perplexity.ai/chat/completions \ --header 'accept: application/json' \ --header 'content-type: application/json' \ --header "Authorization: Bearer ${PERPLEXITY_API_KEY}" \ --data '{ "model": "mistral-7b-instruct", "stream": false, "max_tokens": 1024, "frequency_penalty": 1, "temperature": 0.0, "messages": [ { "role": "system", "content": "Be precise and concise in your responses." }, { "role": "user", "content": "How many stars are there in our galaxy?" } ] }'
Which yields the following response, having content-type: application/json
{ "id": "3fbf9a47-ac23-446d-8c6b-d911e190a898", "model": "mistral-7b-instruct", "object": "chat.completion", "created": 1765322, "choices": [ { "index": 0, "finish_reason": "stop", "message": { "role": "assistant", "content": " The Milky Way galaxy contains an estimated 200-400 billion stars.." }, "delta": { "role": "assistant", "content": " The Milky Way galaxy contains an estimated 200-400 billion stars.." } } ], "usage": { "prompt_tokens": 40, "completion_tokens": 22, "total_tokens": 62 } }
Here is an example Python call:
from openai import OpenAI YOUR_API_KEY = "INSERT API KEY HERE" messages = [ { "role": "system", "content": ( "You are an artificial intelligence assistant and you need to " "engage in a helpful, detailed, polite conversation with a user." ), }, { "role": "user", "content": ( "Count to 100, with a comma between each number and no newlines. " "E.g., 1, 2, 3, ..." ), }, ] client = OpenAI(api_key=YOUR_API_KEY, base_url="https://api.perplexity.ai") # demo chat completion without streaming response = client.chat.completions.create( model="mistral-7b-instruct", messages=messages, ) print(response) # demo chat completion with streaming response_stream = client.chat.completions.create( model="mistral-7b-instruct", messages=messages, stream=True, ) for response in response_stream: print(response)
We currently support Mistral 7B, Llama 13B, Code Llama 34B, Llama 70B, and the API is conveniently OpenAI client-compatible for easy integration with existing applications.
For more information, please visit our API documentation and Quickstart Guide.
What’s Next
In the near future, pplx-api will support:
Custom Perplexity LLMs and other open-source LLMs.
Custom Perplexity embeddings and open-source embeddings.
Dedicated API pricing structure with general access after public beta is phased out.
Perplexity RAG-LLM API with grounding for facts and citations.
Reach out to api@perplexity.ai if you are interested if any of these use cases.
This is also the start of our Perplexity Blog post series. In our next post, we will share a deep dive on A100 vs H100 performance comparison for LLM inference. Stay tuned!
We’re hiring! If you want to work on a product deployed at a massive scale and build thoughtfully designed, carefully optimized generative and large language model infrastructure with us, please join us.
Follow us on Twitter, LinkedIn and join our Discord for more discussion.
Authors:
Lauren Yang, Kevin Hu, Aarash Heydari, William Zhang, Dmitry Pervukhin, Grigorii Alekseev, Alexandr Yarats
Data Privacy
By choosing pplx-api, you can harness the full potential of LLMs while safeguarding the privacy and trust of your users and customers. We understand the importance of protecting your personal information and are committed to maintaining the security and privacy of our users. API data is automatically deleted after 30 days, and we never train on any data transmitted via the pplx-api. Users have the option to opt out of data retention in their account settings. Find our API privacy policy here.
Please note: The below have been deprecated for current models. Learn more about our APIs
We’re excited to announce pplx-api, designed to be one of the fastest ways to access Mistral 7B, Llama2 13B, Code Llama 34B, Llama2 70B, replit-code-v1.5-3b models. pplx-api makes it easy for developers to integrate cutting-edge open-source LLMs into their projects.
Our pplx-api provides:
Ease of use: developers can use state-of-the-art open-source models off-the-shelf and get started within minutes with a familiar REST API.
Blazing fast inference: our thoughtfully designed inference system is efficient and achieves up to 2.9x lower latency than Replicate and 3.1x lower latency than Anyscale.
Battle tested infrastructure: pplx-api is proven to be reliable, serving production-level traffic in both our Perplexity answer engine and our Labs playground.
One-stop shop for open-source LLMs: our team is dedicated to adding new open-source models as they arrive. For example, we added Llama and Mistral models within a few hours of launch without pre-release access.
pplx-api is in public beta and is free for users with a Perplexity Pro subscription.
Use pplx-api for a casual weekend hackathon or as a commercial solution to build new and innovative products. We hope to learn how people can build cool and innovative products with our API through this release. Please reach out to api@perplexity.ai if you have a business use case for pplx-api. We would love to hear from you!
Benefits of pplx-api
Ease of Use
LLM deployment and inference require significant infrastructure undertaking to make model serving performant and cost-efficient. Developers can use our API out-of-the-box, without deep knowledge of C++/CUDA or access to GPUs, while still enjoying the state-of-the-art performance. Our LLM inference also abstracts the complexity and necessity of managing your own hardware, further adding to your ease of use.
Blazing Fast Inference
Perplexity’s LLM API is carefully designed and optimized for fast inference. To achieve this, we built a proprietary LLM inference infrastructure around NVIDIA’s TensortRT-LLM that is served on A100 GPUs provided by AWS. Learn more in the Overview of pplx-api Infrastructure section. As a result, pplx-api is one of the fastest Llama and Mistral APIs commercially available.
To benchmark against existing solutions, we compared the latency of pplx-api with other LLM inference libraries. In our experiments, pplx-api achieves up to 2.92x faster overall latency compared to Text Generation Inference (TGI), and up to 4.35x faster initial response latency. For this experiment, we compared TGI and Perplexity’s inference for single-stream and server scenarios on 2 A100 GPUs using a Llama-2-13B-chat model sharded across both GPUs. For the single-stream scenario, the server processes one request after another. In the server scenario, the client sends requests according to a Poisson distribution with varying request rates to emulate a varying load. For the request rate, we perform a small sweep up to a maximum of 1 request / second, the maximum throughput sustained by TGI. We used real-world data with a variety of input and output token lengths to simulate production behavior. The requests average ~700 input tokens and ~550 output tokens.
Using the same inputs and sending a single stream of requests, we also measured the mean latencies of Replicate’s and Anyscale’s APIs for this same model to gather a performance baseline against other existing APIs.
Using the same experimental setup, we compared the maximum throughput of pplx-api against TGI, with decoding speed as a latency constraint. In our experiments, pplx-api processes tokens 1.90x-6.75x faster than TGI, and TGI entirely fails to satisfy our stricter latency constraints at 60 and 80 tokens/second. We evaluate TGI under the same hardware and load conditions that we used to evaluate pplx-api. Comparing this metric with Replicate and Anyscale is not possible since we cannot control their hardware and load factors.
For reference, the average human reading speed is 5 tokens/seconds, meaning pplx-api is able to serve at a rate faster than one can read.
Overview of pplx-api infrastructure
Achieving these latency numbers requires a combination of state-of-the-art software and hardware.
AWS p4d instances powered by NVIDIA A100 GPUs set the stage as the most cost-effective and reliable option for scaling out GPUs with best-in-class clock speeds.
For software to take advantage of this hardware, we run NVIDIA’s TensorRT-LLM, an open-source library that accelerates and optimizes LLM inference. TensorRT-LLM wraps TensorRT’s deep learning compiler and includes the latest optimized kernels made for cutting-edge implementations of FlashAttention and masked multi-head attention (MHA) for the context and generation phases of LLM model execution.
From here, the backbone of AWS and its robust integration with Kubernetes empower us to scale elastically beyond hundreds of GPUs and minimize downtime and network overhead.
Use Case: Our API in Production
pplx-api In Perplexity: Cost Reduction and Reliability
Our API is already powering one of Perplexity’s core product features. Just switching a single feature from an external API to pplx-api resulted in cost savings of $0.62M/year, approximately a 4x reduction in costs. We ran A/B tests and monitored infrastructure metrics to ensure no quality degradation. Over the course of 2 weeks, we observed no statistically significant difference in the A/B test. Additionally, pplx-api could sustain a daily load of over one million requests, totaling almost one billion processed tokens daily.
The results of this initial exploration are very encouraging, and we anticipate pplx-api to power more of our product features over time.
pplx-api in Perplexity Labs: Open Source Inference Ecosystem
We also use pplx-api to power Perplexity Labs, our model playground serving various open-source models.
Our team is committed to providing access to the latest state-of-the-art open-sourced LLMs. We integrated Mistral 7B, Code Llama 34b, and all Llama 2 models in a matter of hours after their release, and plan to do so as more capable and open-source LLMs become available.
Get Started with Perplexity’s AI API
You can access the pplx-api REST API using HTTPS requests. Authenticating into pplx-api involves the following steps:
Generate an API key through the Perplexity Account Settings Page. The API key is a long-lived access token that can be used until it is manually refreshed or deleted.
Send the API key as a bearer token in the
Authorizationheader with each pplx-api request.
In the following example, PERPLEXITY_API_KEY is an environment variable bound to a key generated using the above instructions. CURL is used to submit a chat completion request.
curl -X POST \ --url https://api.perplexity.ai/chat/completions \ --header 'accept: application/json' \ --header 'content-type: application/json' \ --header "Authorization: Bearer ${PERPLEXITY_API_KEY}" \ --data '{ "model": "mistral-7b-instruct", "stream": false, "max_tokens": 1024, "frequency_penalty": 1, "temperature": 0.0, "messages": [ { "role": "system", "content": "Be precise and concise in your responses." }, { "role": "user", "content": "How many stars are there in our galaxy?" } ] }'
Which yields the following response, having content-type: application/json
{ "id": "3fbf9a47-ac23-446d-8c6b-d911e190a898", "model": "mistral-7b-instruct", "object": "chat.completion", "created": 1765322, "choices": [ { "index": 0, "finish_reason": "stop", "message": { "role": "assistant", "content": " The Milky Way galaxy contains an estimated 200-400 billion stars.." }, "delta": { "role": "assistant", "content": " The Milky Way galaxy contains an estimated 200-400 billion stars.." } } ], "usage": { "prompt_tokens": 40, "completion_tokens": 22, "total_tokens": 62 } }
Here is an example Python call:
from openai import OpenAI YOUR_API_KEY = "INSERT API KEY HERE" messages = [ { "role": "system", "content": ( "You are an artificial intelligence assistant and you need to " "engage in a helpful, detailed, polite conversation with a user." ), }, { "role": "user", "content": ( "Count to 100, with a comma between each number and no newlines. " "E.g., 1, 2, 3, ..." ), }, ] client = OpenAI(api_key=YOUR_API_KEY, base_url="https://api.perplexity.ai") # demo chat completion without streaming response = client.chat.completions.create( model="mistral-7b-instruct", messages=messages, ) print(response) # demo chat completion with streaming response_stream = client.chat.completions.create( model="mistral-7b-instruct", messages=messages, stream=True, ) for response in response_stream: print(response)
We currently support Mistral 7B, Llama 13B, Code Llama 34B, Llama 70B, and the API is conveniently OpenAI client-compatible for easy integration with existing applications.
For more information, please visit our API documentation and Quickstart Guide.
What’s Next
In the near future, pplx-api will support:
Custom Perplexity LLMs and other open-source LLMs.
Custom Perplexity embeddings and open-source embeddings.
Dedicated API pricing structure with general access after public beta is phased out.
Perplexity RAG-LLM API with grounding for facts and citations.
Reach out to api@perplexity.ai if you are interested if any of these use cases.
This is also the start of our Perplexity Blog post series. In our next post, we will share a deep dive on A100 vs H100 performance comparison for LLM inference. Stay tuned!
We’re hiring! If you want to work on a product deployed at a massive scale and build thoughtfully designed, carefully optimized generative and large language model infrastructure with us, please join us.
Follow us on Twitter, LinkedIn and join our Discord for more discussion.
Authors:
Lauren Yang, Kevin Hu, Aarash Heydari, William Zhang, Dmitry Pervukhin, Grigorii Alekseev, Alexandr Yarats
Data Privacy
By choosing pplx-api, you can harness the full potential of LLMs while safeguarding the privacy and trust of your users and customers. We understand the importance of protecting your personal information and are committed to maintaining the security and privacy of our users. API data is automatically deleted after 30 days, and we never train on any data transmitted via the pplx-api. Users have the option to opt out of data retention in their account settings. Find our API privacy policy here.
Please note: The below have been deprecated for current models. Learn more about our APIs
We’re excited to announce pplx-api, designed to be one of the fastest ways to access Mistral 7B, Llama2 13B, Code Llama 34B, Llama2 70B, replit-code-v1.5-3b models. pplx-api makes it easy for developers to integrate cutting-edge open-source LLMs into their projects.
Our pplx-api provides:
Ease of use: developers can use state-of-the-art open-source models off-the-shelf and get started within minutes with a familiar REST API.
Blazing fast inference: our thoughtfully designed inference system is efficient and achieves up to 2.9x lower latency than Replicate and 3.1x lower latency than Anyscale.
Battle tested infrastructure: pplx-api is proven to be reliable, serving production-level traffic in both our Perplexity answer engine and our Labs playground.
One-stop shop for open-source LLMs: our team is dedicated to adding new open-source models as they arrive. For example, we added Llama and Mistral models within a few hours of launch without pre-release access.
pplx-api is in public beta and is free for users with a Perplexity Pro subscription.
Use pplx-api for a casual weekend hackathon or as a commercial solution to build new and innovative products. We hope to learn how people can build cool and innovative products with our API through this release. Please reach out to api@perplexity.ai if you have a business use case for pplx-api. We would love to hear from you!
Benefits of pplx-api
Ease of Use
LLM deployment and inference require significant infrastructure undertaking to make model serving performant and cost-efficient. Developers can use our API out-of-the-box, without deep knowledge of C++/CUDA or access to GPUs, while still enjoying the state-of-the-art performance. Our LLM inference also abstracts the complexity and necessity of managing your own hardware, further adding to your ease of use.
Blazing Fast Inference
Perplexity’s LLM API is carefully designed and optimized for fast inference. To achieve this, we built a proprietary LLM inference infrastructure around NVIDIA’s TensortRT-LLM that is served on A100 GPUs provided by AWS. Learn more in the Overview of pplx-api Infrastructure section. As a result, pplx-api is one of the fastest Llama and Mistral APIs commercially available.
To benchmark against existing solutions, we compared the latency of pplx-api with other LLM inference libraries. In our experiments, pplx-api achieves up to 2.92x faster overall latency compared to Text Generation Inference (TGI), and up to 4.35x faster initial response latency. For this experiment, we compared TGI and Perplexity’s inference for single-stream and server scenarios on 2 A100 GPUs using a Llama-2-13B-chat model sharded across both GPUs. For the single-stream scenario, the server processes one request after another. In the server scenario, the client sends requests according to a Poisson distribution with varying request rates to emulate a varying load. For the request rate, we perform a small sweep up to a maximum of 1 request / second, the maximum throughput sustained by TGI. We used real-world data with a variety of input and output token lengths to simulate production behavior. The requests average ~700 input tokens and ~550 output tokens.
Using the same inputs and sending a single stream of requests, we also measured the mean latencies of Replicate’s and Anyscale’s APIs for this same model to gather a performance baseline against other existing APIs.
Using the same experimental setup, we compared the maximum throughput of pplx-api against TGI, with decoding speed as a latency constraint. In our experiments, pplx-api processes tokens 1.90x-6.75x faster than TGI, and TGI entirely fails to satisfy our stricter latency constraints at 60 and 80 tokens/second. We evaluate TGI under the same hardware and load conditions that we used to evaluate pplx-api. Comparing this metric with Replicate and Anyscale is not possible since we cannot control their hardware and load factors.
For reference, the average human reading speed is 5 tokens/seconds, meaning pplx-api is able to serve at a rate faster than one can read.
Overview of pplx-api infrastructure
Achieving these latency numbers requires a combination of state-of-the-art software and hardware.
AWS p4d instances powered by NVIDIA A100 GPUs set the stage as the most cost-effective and reliable option for scaling out GPUs with best-in-class clock speeds.
For software to take advantage of this hardware, we run NVIDIA’s TensorRT-LLM, an open-source library that accelerates and optimizes LLM inference. TensorRT-LLM wraps TensorRT’s deep learning compiler and includes the latest optimized kernels made for cutting-edge implementations of FlashAttention and masked multi-head attention (MHA) for the context and generation phases of LLM model execution.
From here, the backbone of AWS and its robust integration with Kubernetes empower us to scale elastically beyond hundreds of GPUs and minimize downtime and network overhead.
Use Case: Our API in Production
pplx-api In Perplexity: Cost Reduction and Reliability
Our API is already powering one of Perplexity’s core product features. Just switching a single feature from an external API to pplx-api resulted in cost savings of $0.62M/year, approximately a 4x reduction in costs. We ran A/B tests and monitored infrastructure metrics to ensure no quality degradation. Over the course of 2 weeks, we observed no statistically significant difference in the A/B test. Additionally, pplx-api could sustain a daily load of over one million requests, totaling almost one billion processed tokens daily.
The results of this initial exploration are very encouraging, and we anticipate pplx-api to power more of our product features over time.
pplx-api in Perplexity Labs: Open Source Inference Ecosystem
We also use pplx-api to power Perplexity Labs, our model playground serving various open-source models.
Our team is committed to providing access to the latest state-of-the-art open-sourced LLMs. We integrated Mistral 7B, Code Llama 34b, and all Llama 2 models in a matter of hours after their release, and plan to do so as more capable and open-source LLMs become available.
Get Started with Perplexity’s AI API
You can access the pplx-api REST API using HTTPS requests. Authenticating into pplx-api involves the following steps:
Generate an API key through the Perplexity Account Settings Page. The API key is a long-lived access token that can be used until it is manually refreshed or deleted.
Send the API key as a bearer token in the
Authorizationheader with each pplx-api request.
In the following example, PERPLEXITY_API_KEY is an environment variable bound to a key generated using the above instructions. CURL is used to submit a chat completion request.
curl -X POST \ --url https://api.perplexity.ai/chat/completions \ --header 'accept: application/json' \ --header 'content-type: application/json' \ --header "Authorization: Bearer ${PERPLEXITY_API_KEY}" \ --data '{ "model": "mistral-7b-instruct", "stream": false, "max_tokens": 1024, "frequency_penalty": 1, "temperature": 0.0, "messages": [ { "role": "system", "content": "Be precise and concise in your responses." }, { "role": "user", "content": "How many stars are there in our galaxy?" } ] }'
Which yields the following response, having content-type: application/json
{ "id": "3fbf9a47-ac23-446d-8c6b-d911e190a898", "model": "mistral-7b-instruct", "object": "chat.completion", "created": 1765322, "choices": [ { "index": 0, "finish_reason": "stop", "message": { "role": "assistant", "content": " The Milky Way galaxy contains an estimated 200-400 billion stars.." }, "delta": { "role": "assistant", "content": " The Milky Way galaxy contains an estimated 200-400 billion stars.." } } ], "usage": { "prompt_tokens": 40, "completion_tokens": 22, "total_tokens": 62 } }
Here is an example Python call:
from openai import OpenAI YOUR_API_KEY = "INSERT API KEY HERE" messages = [ { "role": "system", "content": ( "You are an artificial intelligence assistant and you need to " "engage in a helpful, detailed, polite conversation with a user." ), }, { "role": "user", "content": ( "Count to 100, with a comma between each number and no newlines. " "E.g., 1, 2, 3, ..." ), }, ] client = OpenAI(api_key=YOUR_API_KEY, base_url="https://api.perplexity.ai") # demo chat completion without streaming response = client.chat.completions.create( model="mistral-7b-instruct", messages=messages, ) print(response) # demo chat completion with streaming response_stream = client.chat.completions.create( model="mistral-7b-instruct", messages=messages, stream=True, ) for response in response_stream: print(response)
We currently support Mistral 7B, Llama 13B, Code Llama 34B, Llama 70B, and the API is conveniently OpenAI client-compatible for easy integration with existing applications.
For more information, please visit our API documentation and Quickstart Guide.
What’s Next
In the near future, pplx-api will support:
Custom Perplexity LLMs and other open-source LLMs.
Custom Perplexity embeddings and open-source embeddings.
Dedicated API pricing structure with general access after public beta is phased out.
Perplexity RAG-LLM API with grounding for facts and citations.
Reach out to api@perplexity.ai if you are interested if any of these use cases.
This is also the start of our Perplexity Blog post series. In our next post, we will share a deep dive on A100 vs H100 performance comparison for LLM inference. Stay tuned!
We’re hiring! If you want to work on a product deployed at a massive scale and build thoughtfully designed, carefully optimized generative and large language model infrastructure with us, please join us.
Follow us on Twitter, LinkedIn and join our Discord for more discussion.
Authors:
Lauren Yang, Kevin Hu, Aarash Heydari, William Zhang, Dmitry Pervukhin, Grigorii Alekseev, Alexandr Yarats
Data Privacy
By choosing pplx-api, you can harness the full potential of LLMs while safeguarding the privacy and trust of your users and customers. We understand the importance of protecting your personal information and are committed to maintaining the security and privacy of our users. API data is automatically deleted after 30 days, and we never train on any data transmitted via the pplx-api. Users have the option to opt out of data retention in their account settings. Find our API privacy policy here.