
Meet New Sonar: A Blazing Fast Model Optimized for Perplexity Search

Starting today, all Perplexity Pro users will be able to try out the latest version of Sonar, Perplexity's in-house model that is optimized for answer quality and user experience. Built on top of Llama 3.3 70B, Sonar has been further trained to enhance answer factuality and readability for Perplexity’s default search mode.
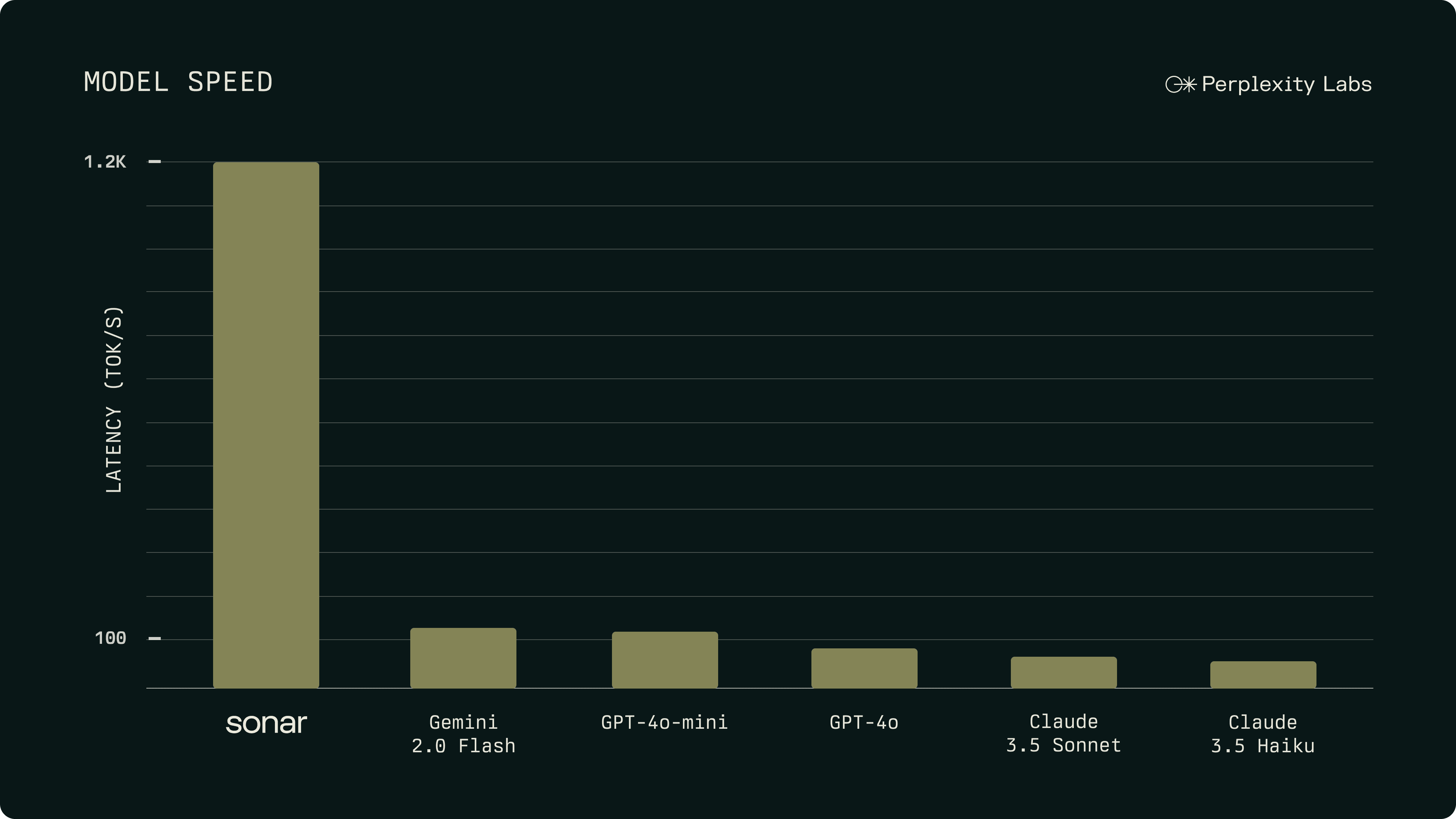
Through comprehensive online A/B testing, we have found that Sonar significantly outperforms models in its class, like GPT-4o mini and Claude 3.5 Haiku, while closely matching or exceeding the performance of frontier models like GPT-4o and Claude 3.5 Sonnet for user satisfaction. Powered by Cerebras inference infrastructure, Sonar runs at a blazing fast speed of 1200 tokens per second — enabling nearly instant answer generation.
Perplexity Users Prefer Sonar
We conducted extensive online A/B testing of Sonar to measure user satisfaction — a key metric that is strongly correlated with product usage and retention. This metric captures how satisfied and engaged users are when asking questions on Perplexity.
Our evaluations show that Sonar surpasses both GPT-4o mini and Claude 3.5 Haiku by a substantial margin. We also compared Sonar against more expensive frontier models and found that it outperforms Claude 3.5 Sonnet, while closely approaching the performance of GPT-4o at a fraction of the price and more than 10x the speed.

Blazing Fast Speed Enables Instant Answers
Powered by Cerebras inference infrastructure, Sonar delivers answers at blazing fast speeds, achieving a decoding throughput that is nearly 10x faster than comparable models like Gemini 2.0 Flash. This enables nearly instant answer generation, which makes Sonar ideal for quick information retrieval or detailed question answering use cases.

Sonar Excels at Providing Factual and High Quality Answers
We optimized Sonar across two critical dimensions that strongly correlate with user satisfaction — answer factuality and readability.
Answer Factuality: Measures how well a model can answer questions using facts that are grounded in search results, and its ability to resolve conflicting or missing information
Readability: Measures a model’s ability to provide a concise and detailed answer with the appropriate use of markdown formatting for organizing text
Our results demonstrate that Sonar significantly improves these aspects compared to the base model, Llama 3.3 70B Instruct, and even surpasses other frontier models in these key areas†.
Additionally, Sonar also exceeds in-class models like GPT-4o mini and Claude 3.5 Haiku on academic benchmarks that measure user instruction following and world knowledge.
IFEval: Measures how well a model adheres to user-provided instructions
MMLU: Evaluates world knowledge across diverse domains

How Sonar Answers Questions
What does increased factuality and readability look like in practice? Compare these searches, which were conducted on both Sonar and other models to see the difference.




Use Sonar Today
Sonar excels at providing fast and accurate answers, making it a great model for everyday use. Perplexity Pro users can make Sonar their default model in their settings. It can also be used via the Sonar API offering*.

Footnotes
†These evaluations are graded on a scale from 0 to 100, where higher is better
*The Sonar model served through the API does not yet run on Cerebras inference infrastructure, but it is coming out shortly