
Perplexity Sonar Dominates New Search Arena Evaluation

TL;DR
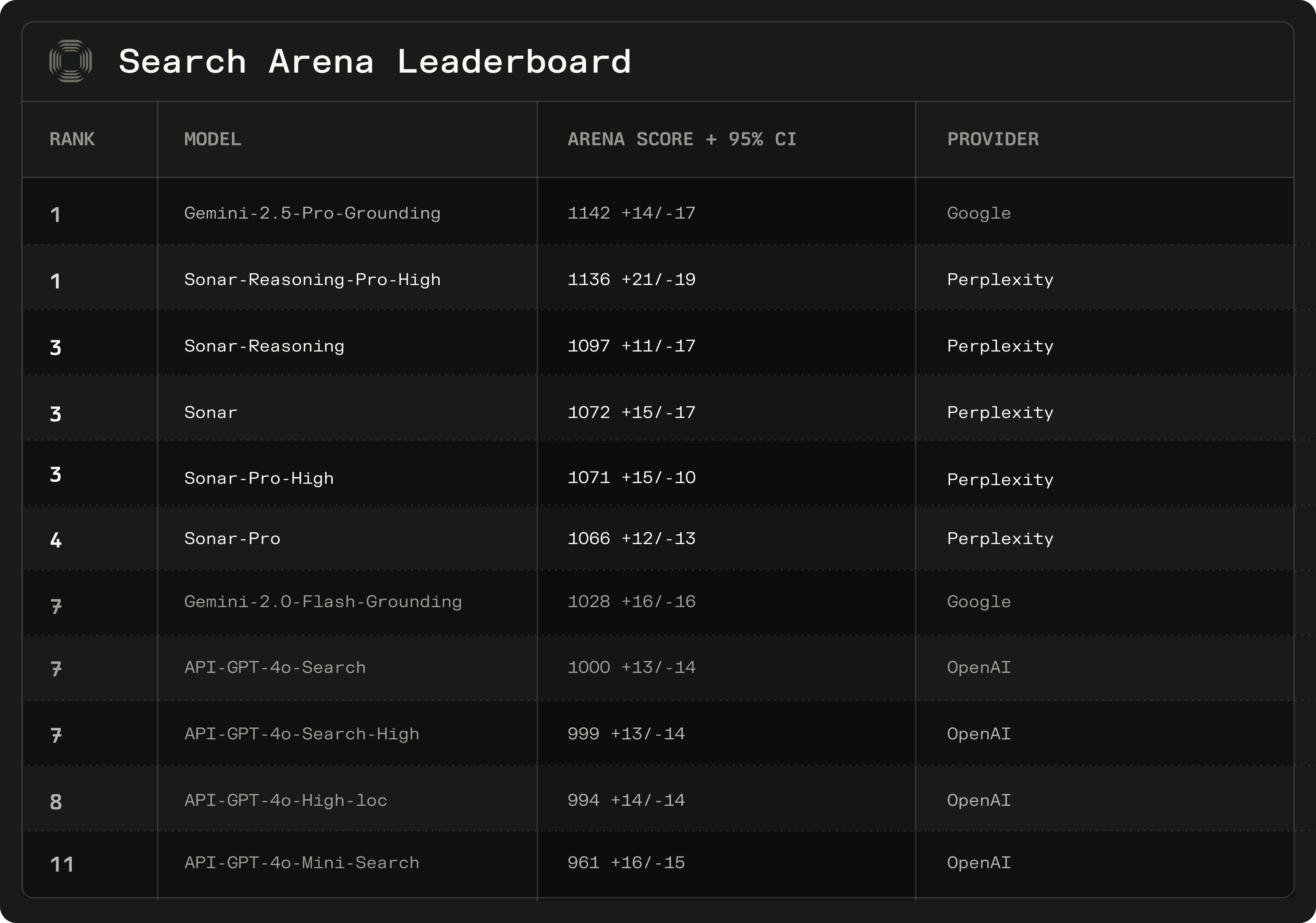
Co #1 Rank: Sonar-Reasoning-Pro-High achieved an Arena Score of 1136 (±21/−19), statistically tied for first place with Google's Gemini-2.5-Pro-Grounding (1142 +14/-17). In direct head-to-head battles, Sonar-Reasoning-Pro-High beat Gemini-2.5-Pro-Grounding 53% of the time.
Sonar Dominance: Perplexity models secured ranks 1 through 4, significantly outperforming other evaluated models from Google and OpenAI.
Reasoning Advantage: Models incorporating reasoning capabilities (sonar-reasoning-pro and sonar-reasoning) ranked higher, aligning with the general user preference observed for reasoning models (top 3 on the leaderboard).
Depth of Search: Sonar models perform deeper search and consider more sources, on average citing 2-3x more sources than comparable Gemini models.
______
LM Arena just released their new Search Arena leaderboard comparing search-augmented LLM systems based on human preference. Perplexity's Sonar-Reasoning-Pro model has tied for first place with Gemini-2.5-Pro-Grounding with the rest of the Sonar models outperforming Gemini-2.0-Flash-Grounding and all of OpenAI’s web search models.
Search Arena Benchmarking
Unlike SimpleQA's focus on narrow factual accuracy, LM Arena evaluates how models perform on real user queries across coding, writing, research, and recommendations. With Search Arena, evaluation focuses on current events and includes longer, more complex prompts, collecting over 10,000 human preference votes across 11 models. Between March 18 and April 13, 2025, Search Arena asked users to prompt and select which model response better satisfied their information needs.
Sonar Model Performance Results
Perplexity's Sonar models outperformed many of the top state of the art models including Gemini 2.0 Flash and GPT 4o Search. Our Sonar-Reasoning-Pro model achieved a score of 1136, statistically tied with Gemini-2.5-Pro-Grounding (1142) at the top position.
In direct head-to-head battles, Sonar-Reasoning-Pro-High beat Gemini-2.5-Pro-Grounding 53% of the time.

Search Arena's evaluation revealed three factors strongly correlating with human preference:
Longer responses (coeff 0.255, p<0.05)
Higher citation counts (coeff 0.234, p<0.05)
Citations from community web sources
The leaderboard showed clear user preference for reasoning-enhanced models, with Sonar-Reasoning-Pro and Sonar-Reasoning taking two of the top three positions. Control experiments reinforced these findings, showing that controlling for citations caused model rankings to converge, suggesting search depth is a significant performance differentiator.

Perplexity's Sonar models had substantially higher search depth, with ppl-sonar-pro-high citing 2-3x more sources than equivalent Gemini models.
What This Means for Users
For Perplexity users, these results confirm that Sonar models provide best-in-class accuracy, comprehensive source attribution, and high-quality responses across a wide range of topics.
Perplexity Pro users can continue to benefit from these top-performing models by setting Sonar as their default model in settings. API users can access these capabilities through our Sonar API offerings with flexible search modes to balance performance and cost efficiency
While we're proud of this achievement, we remain focused on continuous improvement. The Search Arena evaluation provides valuable insights into user preferences that will inform our ongoing development efforts.
Introduction to Sonar
Join Perplexity co-founder & CTO, Denis Yarats, for an overview of our API on April 24 at 11am PT. Denis will provide an overview of Perplexity's APIs, share benchmark results, and API use cases.
Register here.