
RL Training For Math Reasoning

Introduction and Motivation
Reinforcement Learning (RL) algorithms, especially proximal policy optimization (PPO) and Group Relative Policy Optimization (GRPO), have proven to be essential for improving model capabilities in reasoning related tasks. In this blog we’d like to share the learnings and decision reasonings we experienced when developing RL infra as well as training math-reasoning models with RL. For illustration purpose, the results we show below are based on smaller open source models, but most of them apply to larger models as well.
The goal of the RL model training exploration is two-folds: 1) share our lessons and learnings on how to train models to hit the state-of-the-art math reasoning performance. This equips the team with the right knowledge on data manipulation, data mixing recipes, training best practices, RL algorithm nuances, and general performance optimization experience. 2) Apply these learnings to real production use cases to improve Perplexity products.
A summary of the key findings:
Infrastructure: we’ve developed GRPO algorithm on torchtune library as well as the Nemo suite, with VLLM-based rollout integrated. Nemo will be our short term go-to infra for RL training, while we develop torchtune GRPO support, which will be our preferred infra in the longer-run, for self-contained maintenance (no external dependency) as well as simpler framework architecture.
Math dataset vested: gsm8k, math, NuminaMath, Open Reasoning Zero (ORZ), AIME series.
Math reasoning model training:
Data mixture of different difficulty levels matters
RL proves to be able to further improve large language models (LLMs) reasoning capability beyond supervised fine tuning (SFT)
The capability of base model matters a lot. In particular, long-CoT capability of the base model is important for further scaling with RL.
A good SFT starting checkpoint helps the above. Light SFT serves two purposes:
enable the RL base model to be comfortable with generating long-CoT responses. Without this ability, when RL forces the model to scale it’s response length, self-repeating collapse would happen.
teach some reasoning capability to the base model, enabling the RL process to start higher and learn faster from the start, compared to a model that only knows to generate long-CoT responses with weak reasoning capability.
Training infrastructure exploration
Despite several open source RL training frameworks being available, many of them do not fit our situation. Ideally we’d want the following properties:
Scales well with the large model sizes of our production models.
Good training speed optimizations.
Easy to implement new algorithms and maintain without too much external dependencies.
Simpler and extendable framework architecture design.
Ideally unify with SFT training framework.
Framework comparison
A comparison of the frameworks that we considered [the following table comparison was done in Feb 2025. Note that a lot of the missing algorithms were later implemented.]:

We chose Nemo Aligner as a short term option, and ruled out the rest due to the following reasons:
Nemo-Aligner: due to the most complete features already implemented, as well as partnership support from Nvidia, we chose this option as our short term focus. However, the complex setup with dependencies on multiple repos puts some overhead on maintenance.
torchtune: this is the SFT framework we use at Perplexity. The framework is elegantly designed and easy to extend in general. However, due to being fairly new, the framework lacks a lot of features to be added. We aim to shift to torchtune for RL in the long-run. Once we get Nemo-aligner to a good state, we will invest in maintaining an in-house version of torchtune with our own implementation of desired algorithms.
VeRL: although integrates both FSDP and more powerful Megatron-LM backend, the latter support is very limited due to the community’s demand being mostly on smaller models where FSDP is sufficient. FSDP generally has weaker support for tensor-parallelism, which is crucial for larger models, especially in RL training. However, VeRL quickly become a popular choice for the community, and has developed significantly in the recent months. Given its selling points on throughput optimizations, and multiple recent papers on reasoning/agentic model training based on this framework (e.g. [1], [2]), it’s worth revisiting this option in the near future.
openRLHF: popular in academic community. However, the DeepSpeed backend makes it less scalable to large models. We’ve ruled out this option.
Algorithm development and validation
In this section, we first provide a brief introduction to the GRPO algorithm and discuss the associated technical enhancements that contribute to its implementation complexity. Subsequently, we describe the infrastructure developed to address these challenges.

Comparison of PPO vs GRPO. ReferenBce: https://arxiv.org/abs/2402.03300
PPO is a popular RL algorithm widely used for fine-tuning LLMs due to its simplicity and effectiveness, as depicted above. However, PPO’s reliance on a separate value model introduces significant computational and memory overhead.
To address this limitation, GRPO modifies PPO by removing the separate value model and introducing group-based advantage calculation, as illustrated in figure above. Specifically, generates multiple candidate responses for each input question, computes their reward scores collectively, and determines advantages relative to these grouped outputs. While such innovation simplify certain aspect, they introduce new implementation complexities, such as efficiently generating multiple long-sequence rollouts.
Implementation details
Despite similar RL algorithms (PPO, Reinforce) already in-place in Nemo-Aligner, it’s surprisingly time consuming to make GRPO work properly for our case. A summary of improvements we did include:
GRPO algorithm implementation;
A more robust KL-divergence estimator (details);
Incorporate a format reward and enhance rules for mathematical accuracy (covering both numerical answers and symbolic ground-truth expressions);
Work with Nvidia support team to integrate VLLM-based rollout, which improved rollout efficiency by 30% and also fixed the buggy TensorRT-LLM infra that had log-probability mismatch (see next point)
Log-probability alignment with HF
Note: this effort was by-far the most time-consuming. In order to ensure code correctness, we adopt the following metric to verify the computed log-probabilities from Nemo-Aligner is correct:
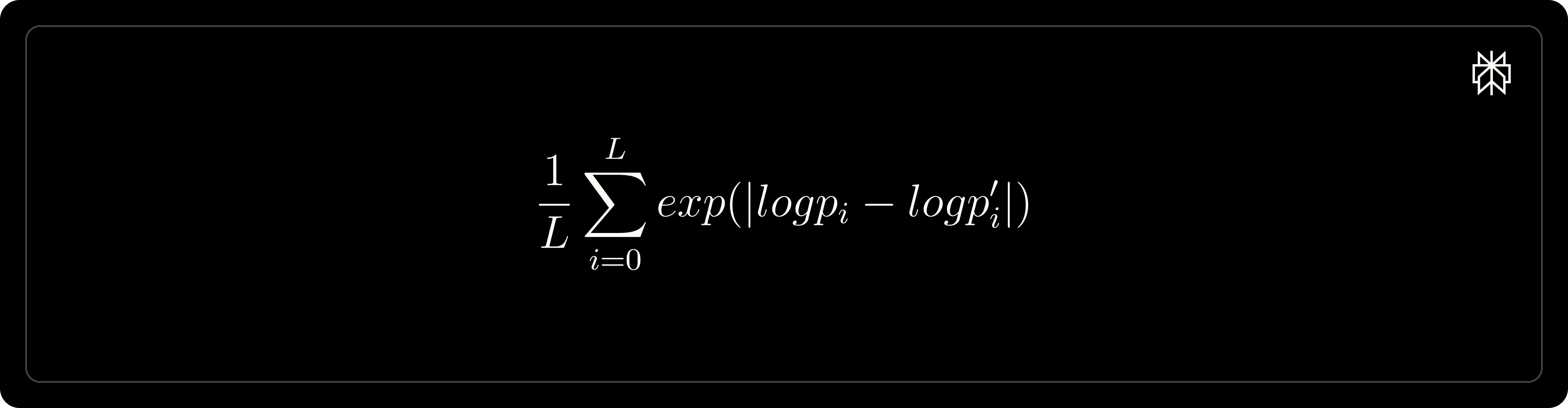
where L is the length of a rollout, the first 𝓁𝑜𝑔𝓅ᵢ is the log-probability on the i-th token from Nemo-Aligner, and second 𝓁𝑜𝑔𝓅'ᵢ is the reference log-probability we get by manually running model.forward on a huggingface model directly. This metric needs to stay very close to 1.0. We went through several iterations of nemo model converter, repo update, and image rebuilding, to reduce the metric from 1e5 down to a normal range within [1, 1.05].
Multiple rounds of hyper-parameter searches to optimize for memory. Due to the fact that GRPO requires multiple samples per-prompt, as well as math reasoning rollouts are usually long, we often end up with cuda OOM issue. Hyper parameters, especially parallelism setup, needs to be carefully picked to ensure smooth training.
Minor issues with dataloader consumption early stopping, and tensor shape issues in corner cases.
Experiments
In this section, we present the experimental setup and results, building upon the previously described infrastructure.
Experimental setup
We evaluate the models on the MATH-500 dataset using the pass@1 metric defined as follows, and report results specifically for pass@1. During evaluation, we set the sampling temperature of 0.7 and a top-𝑝 value of 0.95 to generate k rollouts.
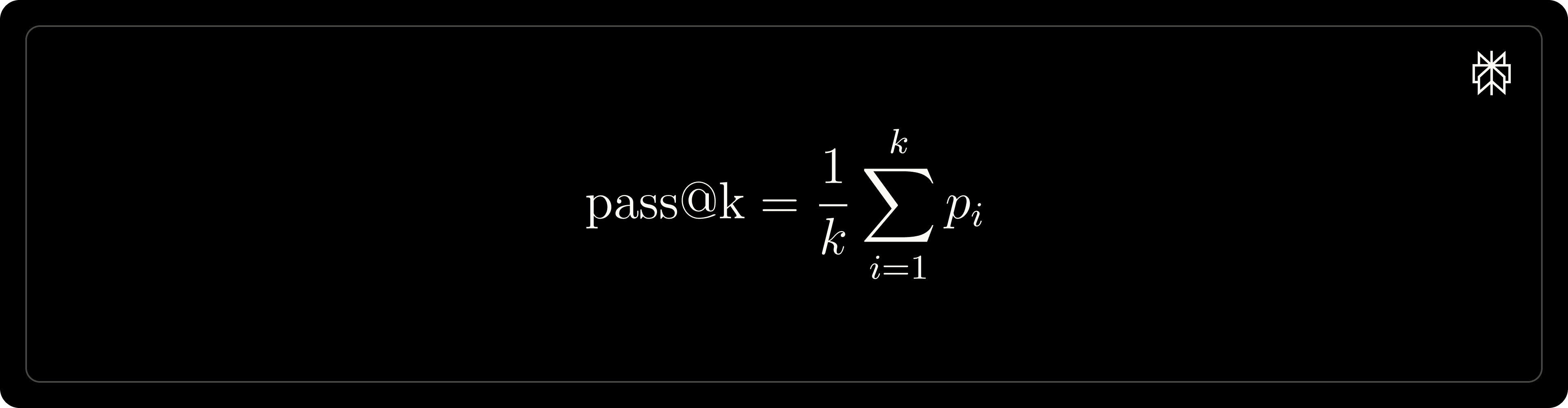
where 𝒫𝒾 denotes the correctness of the i-th response. The training and evaluation prompts are listed below, respectively. Specifically, we are not using system prompt, i.e. the following prompts are prepended into the user message.
# training prompt TRAINING_PROMPT = ( "A conversation between User and Assistant. The user asks a question, and the Assistant solves it. " "The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. " "The reasoning process and answer are enclosed within <think></think> and <answer></answer> tags, respectively, " "i.e., <think>reasoning process here</think> <answer>answer here</answer>. User: {question} Assistant: " )
# Evaluation prompt EVALUATION_PROMPT = ( "You will be given a problem.Please reason step by step, " "and put your final answer within \\boxed{}. " )
Additional experimental configurations are described below.
Model specifications:
We primarily experimented with dense Llama models, selecting our base models from the following two variants due to their suitable size and widespread adoption within the research community. These models serve as baseline references for reasoning performance in our subsequent experiments:
Llama 3.1 8B Instruct
Llama 3.1 8B Base
Dataset details:
The datasets collected and used in our experiments are as outlined below.
Sources | Size | Labeling Models | Difficulty | Usage |
|---|---|---|---|---|
Gsm8k | ~7k | QwQ 32B preview & R1 | Easy | Training |
MATH | ~7k | QwQ 32B preview & R1 | Medium | Training |
Orz (contains MATH) | ~57k | QwQ 32B preview & R1 | Hard | Training |
numinamath | ~250K (filtering) | None | Hard | Training |
MATH-500 | 500 | None | Medium | Evaluation |
Training procedure:
This subsection describes the specific training methods, specifically, the hyper-parameter selection, employed during GRPO-based fine-tuning.
Hyperparameters:
We used the GSM8K dataset for the training in this sub-section.
Learning Rate (LR) and KL coefficient:
We present accuracy results for various combinations of learning rates (LR) and KL coefficients below. (Note that some experimental runs terminated prematurely due to infrastructure-related errors, resulting in slight discrepancies in total training steps.)
Learning Rate/KL coefficient | 0.1 | 0.01 | 0.001 |
|---|---|---|---|
8e-8 | 0.426 | 0.434 | 0.422 |
1e-7 | 0.432 | 0.492 | 0.414 |
3e-7 | 0.470 | 0.488 | 0.470 |
5e-7 | 0.444 | 0.48 | 0.486 |
Analysis of these results indicates that a learning rate of 3e-7 consistently demonstrates stable performance across different KL settings, thus it was adopted for primary experiments. Moreover, experiments revealed improved outcomes with lower KL values, leading us to eliminate the KL term entirely in subsequent primary training runs. Higher learning rates such as 5e-7 and 8e-7 tended to accelerate early convergence, limiting the development of long-chain-of-thought (CoT) reasoning capabilities in late stage.
Temperature:
Temperatures tested: [0.7 (dark red), 0.8 (red), 1.0 (green), 1.1 (purple), 1.2 (blue), 1.3 (grey)]
The figures below are the training accuracy (left) vs the validation accuracy (right).

Temperature | 0.7 | 0.8 | 1 | 1.1 | 1.2 | 1.3 |
|---|---|---|---|---|---|---|
Validation | 0.502 | 0.48 | 0.452 | 0.442 | 0.184 | 0.082 |
Conclusions:
Based on the empirical results presented above, we select a temperature of 1.0 as the default setting, balancing convergence speed and overall accuracy.
Higher temperature settings (e.g., 1.2, 1.3) negatively impact convergence, resulting in instability and failure to achieve satisfactory performance.
Large temperature like, 1.2, 1.3 will make the model fail to converge
While lower temperature values (e.g., 0.7, 0.8 )facilitate rapid initial convergence, these settings typically lead to premature saturation, causing limited performance improvement on the validation set during later stages of training.
Reward models
In our preliminary experiments, we evaluated the following two rule-based reward models proposed in the DeepSeek paper:
Accuracy reward: This reward function assesses the correctness of the model's output by comparing the assistant's provided answers with predefined ground-truth solutions.
Format reward: This reward model encourages the language model to structure its responses in a predefined, consistent format. In our experiments, the desired format requires the LLMs to explicitly separate the reasoning process from the final answer by enclosing them within specific XML-like tags. More concretely, the expected format is shown in
TRAINING_PROMPTlisted above.
Results
Here are the training setup for our primary experiments:
LR = 3e-7, KL coefficient = 0, Temperature = 1, only Accuracy reward.
Main result
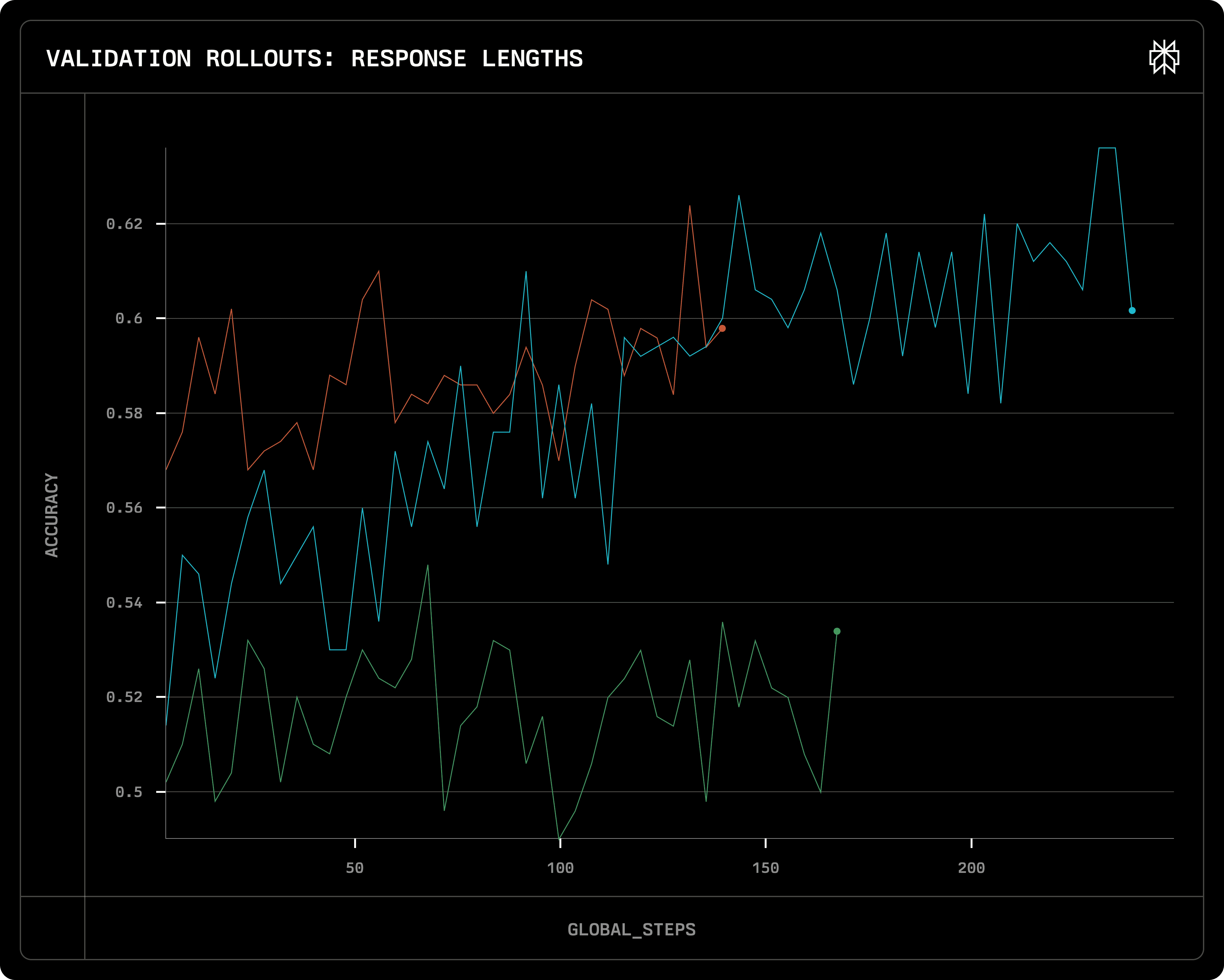
The figure below presents the primary results from this study, showcasing validation accuracy comparisons across three experimental conditions:
Validation on three RL setups: Left: train from SFT-warmed-up model; Mid: train from Llama 3.1 8B instruct; Right: train from Llama 3.1 8B Base
The three lines shown in the figure corresponding to the following setting
[Red] RL fine-tuning on the ORZ dataset initialized from the ORZ-supervised fine-tuned warm-up checkpoint (epoch 4). The SFT data is labeled by QwQ-32B-preview model, which is a CoT reasoning model.
[Green] RL fine-tuning on the ORZ dataset initialized from the vanilla Llama 3.1 8B instruct checkpoint.
[Blue] RL fine-tuning on the ORZ dataset initialized from the vanilla Llama 3.1 8B base checkpoint.
The results highlight two key findings:
RL significantly enhanced the models' mathematical reasoning capabilities, as evidenced by improvements in validation accuracy and increased generation lengths. (Notes: the accuracy of Llama 3.1 8B instruct and ORZ tuned model are about ~0.38 and ~0.60, respectively. The best RL result, Red line in the above graph, achieved 0.70 score on MATH500, which matches similar results in the literatures, e.g. [1], [2])
Prior exposure to long CoT reasoning data during supervised fine-tuning or the pre-training stage substantially accelerated the efficacy and efficiency of subsequent RL fine-tuning. From the curves above, it’s clear that the long-CoT exposure from SFT gets the Red line to start and plateau much higher than the other two. (Note: Contrary to the claims in some papers, our observations suggest that SFT enhances the efficiency of subsequent RL stages. While we hypothesize that SFT may also improve the upper-bound performance of the base model, we have not yet trained the model sufficiently to validate this hypothesis conclusively.)
Analysis of Observed Phenomena
During our experiments, we observed multiple noteworthy phenomena. Here we discuss these phenomena in detail.
Learning rate matters
We found that learning rate in GRPO generally controls 2 things: 1) how fast the learning picks up, and 2) how stable the convergence is. Smaller learning rate causes the learning to progress slower, which is expected. However, with a big learning rate, even though the learning curve climbs fast in early steps, it often leads to model collapse if continuously trained after convergence. In the graph below, the 3 lines corresponds to 3 different learning rates:
Purple:
8e-7,Green:
3e-7,Blue:
1e-7.
With lr=8e-7, the learning plateaus very early, but then causes model to collapse (and response length gets exploded) very fast. With lr=3e-7, learning reaches the same level near the end of 15k steps, and was stable, while with lr=1e-7, the learning is too slow that the training didn’t converge within 15k steps. (All three runs are using adam optimizer, learning rate schedule is constant).
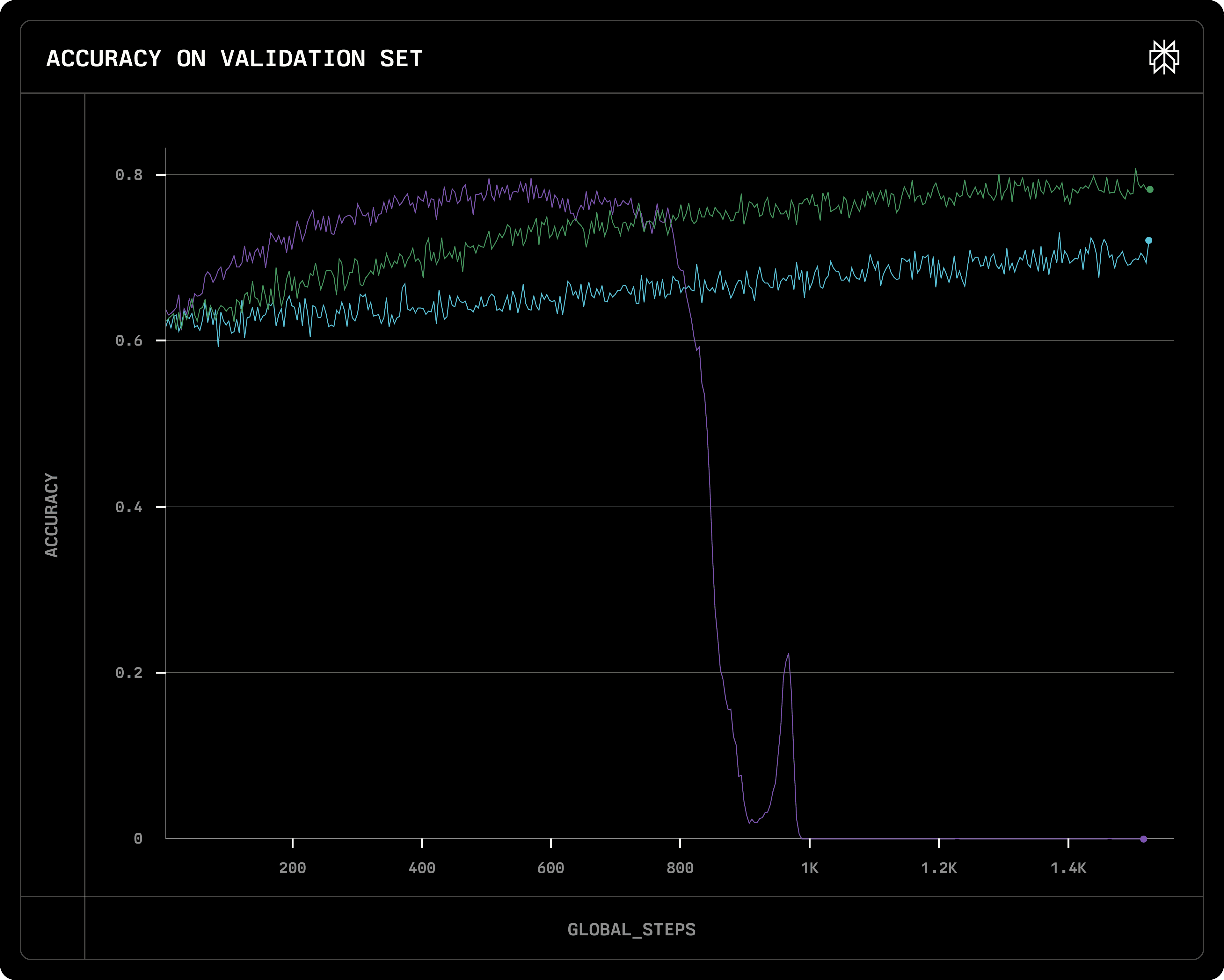
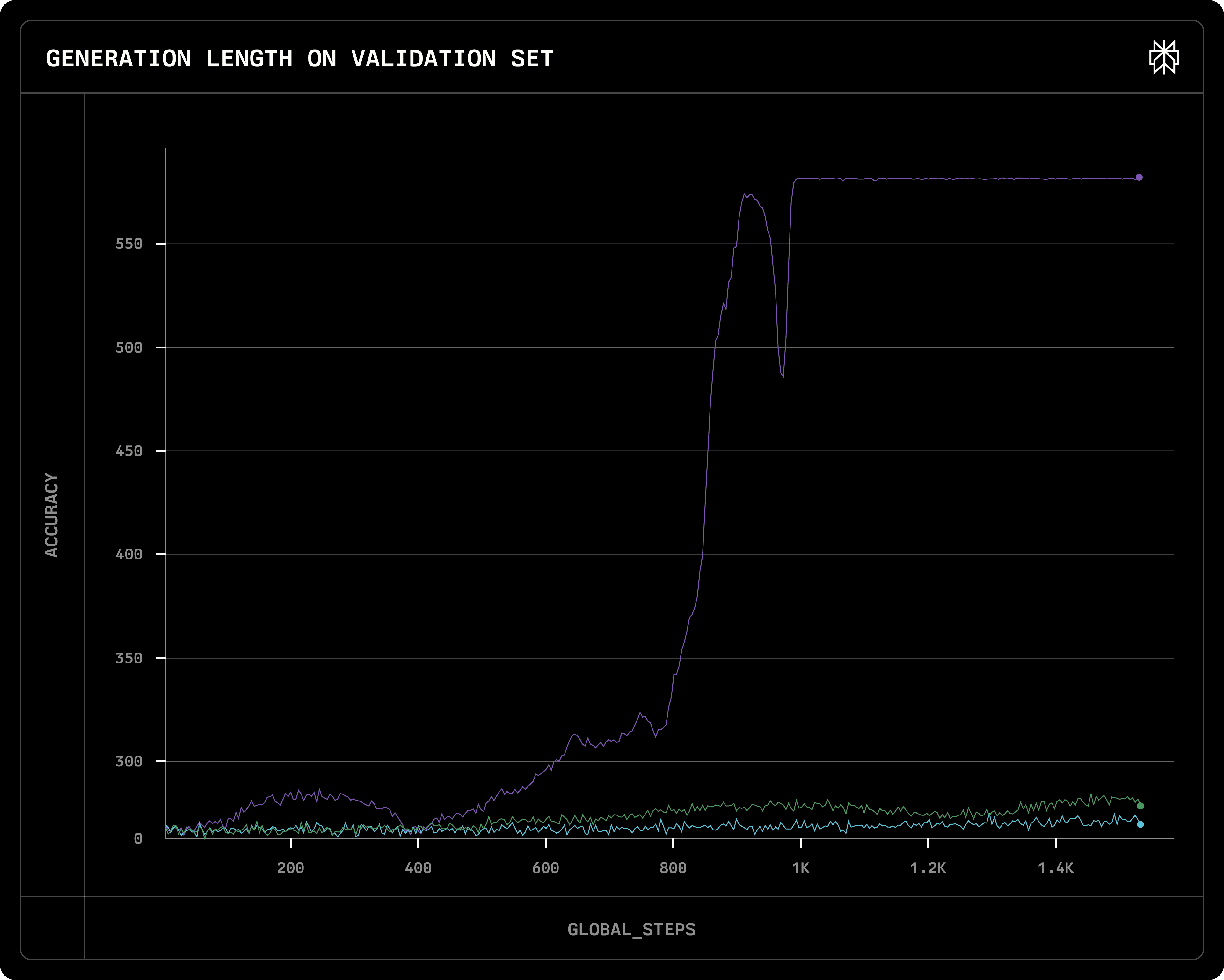
Validation reward (i.e. accuracy) of three runs with different learning rate: Purple: 8e-7, Green: 3e-7; Blue: 1e-7
We will look further into why the reward curve collapses in the following Model Collapse section.
Model collapse
We define model collapse as the sudden deterioration in the generative capabilities of a model during RL training. It’s observed in two primary forms during our experiments: self-repetition collapse and end-of-sequence collapse.
Self-repetition collapse: This form of collapse emerged predominantly in experiments that incorporated a format reward. Initially intended to guide the model toward producing well-structured and interpretable outputs, the format reward required the model to organize its responses using distinct
<think></think>and<answer></answer>tags. However, while promoting structural clarity, we found that this reward signal inadvertently increased the likelihood of collapse via repetition.
Initially, we employed a relatively loose format reward—requiring at least one <think> block and one <answer> block—to encourage adoption of the desired response structure. In the following example, although the final reward converges well, the rollouts started to have severe repetition issue when training steps go beyond 110.

Validation format reward (left), math accuracy (mid) and rollout length (right) with loose format reward
A closer look at the rollouts reveals that after convergence, the model generates a normal thinking process (something without the <think> tags), then the correct answer, then a repetition of the format blocks with empty content (see example below).
<|start_header_id|>assistant<|end_header_id|><think> Let's denote the positive integer as n. When n is expressed in base 8, it forms the number $AB_8$, which can be written as $8A + B$. When n is expressed in base 6, it forms the number $BA_6$, which can be written as $6B + A$. Since both expressions represent the same number n, we can set them equal to each other: $8A + B = 6B + A$ Subtracting A from both sides gives: $7A = 5B$ Dividing both sides by 7 gives: $A=\frac{5}{7}B$ Since A and B are digits, they must be integers. The only way for A to be an integer is if B is a multiple of 7. The smallest possible value of B that satisfies this condition is B = 7. Substituting B = 7 into the equation A = (5/7)B gives: $A=\frac{5}{7} \times 7 = 5$ Now that we have the values of A and B, we can find the decimal value of n. We know that n in base 8 is represented as 57, so the decimal value of n is: $8 \times 5 + 7 = 40 + 7 = 47$ Therefore, the positive integer in decimal is $\boxed{47}$. </think> </answer> </think> </answer> </think> </answer> </think> </answer> </think>
To address this, we experimented with a stricter format reward requiring exactly one <think> block followed by one <answer> block. However, this adjustment exacerbated the problem: not only did repetition persist, but the accuracy of the answers also deteriorated [link].
Validation format reward (left), math accuracy (mid) and rollout length (right) with strict format reward
One illustrative example is attached below:
<|start_header_id|>assistant<|end_header_id|><think> To find the matrix $\mathbf{M}$, we can use the property of linear transformations that represents the transformation of vector $\mathbf{v}$ as $-4\mathbf{v}$. This means that the matrix $\mathbf{M}$ must be a scalar multiple of the identity matrix, where the scalar is $-4$. </think> <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </think> ........ <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </think> <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}}</answer>
Based on these observations, we initially hypothesized that the format reward itself was the primary cause of the collapse. To test this, we conducted follow-up experiments with the format reward entirely removed which leads us to the following end-of-sequence collapse.
End-of-sequence collapse: this collapse occurs when the model reaches the maximum allowed token generation limit, subsequently causing a performance breakdown.
This phenomenon likely results from ill-defined loss scenarios, where multiple outputs from a single input query uniformly receive identical rewards. This happens when all rollouts of a prompt are cut-off, causing the reward to all be 0, thus the advantage is also 0. Let’s take a further look at the reward curve collapsing example in the Learning Rate Matters section. In this case, KL coefficient is set to 0. For prompts whose rollouts are all cut-off, it’s impossible to get the policy away from this state, because policy gradient becomes 0 [see Eq 2 in Limitations section]. The math accuracy starts to decrease as more rollouts get cut-off, and then got stuck in this situation. In the following graphs, we can see a clear correlation between the cut-off rate and train rollout reward drop.

End-of-sequence collapse. Training reward collapse aligns with rollout cut-off
Note that the end-of-sequence collapse is also observed in Demystifying Long Chain-of-Thought Reasoning in LLMs, even with the KL-term added. Their paper proposed a reward shaping approach that tries to control the rollout sequence length. However, our experiments show that while reward shaping successfully suppressed the generation length (length collapse), it hindered model from learning the correct reasoning and answer, causing much lower math accuracy throughout training:
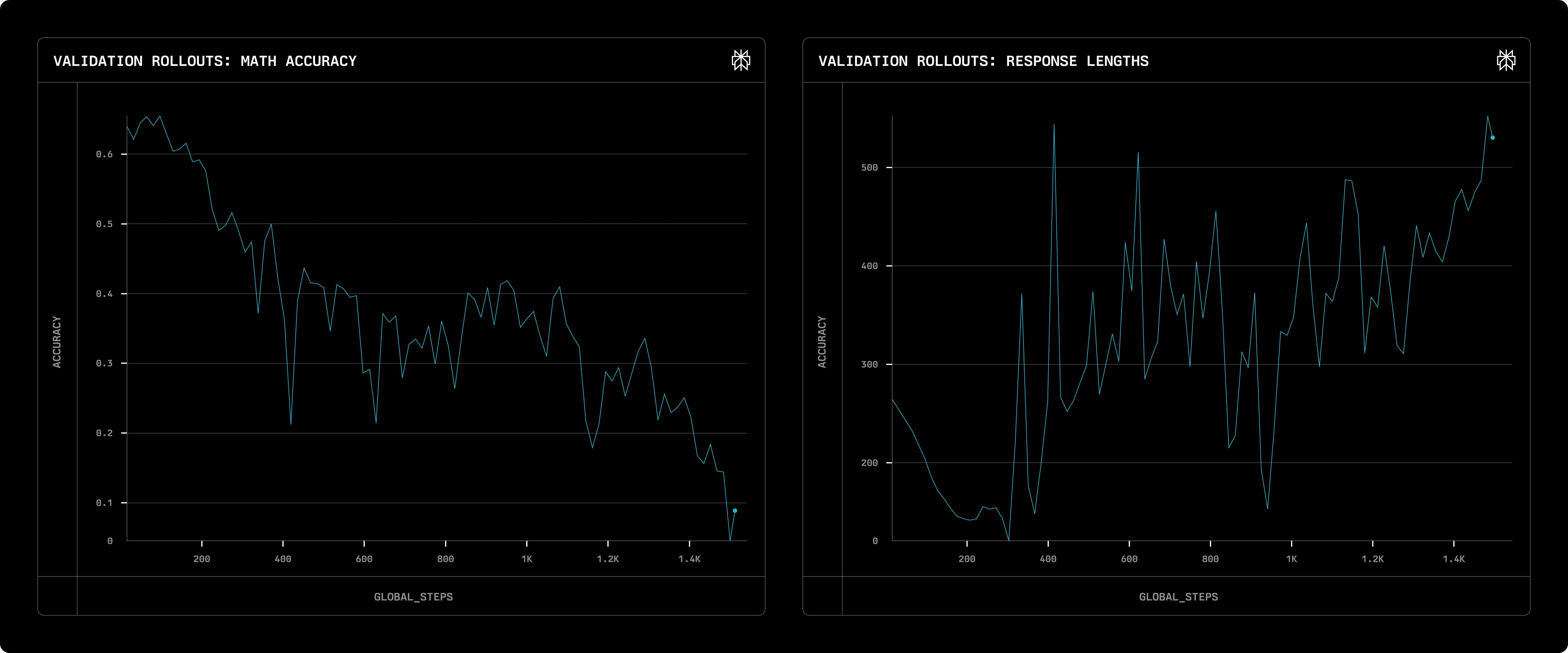
Validation accuracy and response length with reward shaping
In the Limitations section, we will propose new ways to handle this situation. Combining the previous self-repetition example and main results above, it seems with a based model that’s not exposed to long CoT reasoning answers, RL would cause the model to brokenly scale up response length and eventually collapse with repetition.
Base model capability
We conducted an ablation study to investigate the impact of SFT on subsequent RL performance. Models were first fine-tuned using datasets of varying difficulty levels—ORZ (difficult), MATH (medium), and GSM8K (easy)—followed by RL fine-tuning exclusively on the ORZ dataset.
Validation accuracy on different initial models
[Blue]: SFT on ORZ (difficulty: difficult) data then RL on ORZ
[Red]: SFT on MATH (difficulty: medium) data then RL on ORZ
[Green]: SFT on GSM8K (difficulty: easy) data then RL on ORZ
The results clearly indicated that employing a diverse mixture of difficulty levels in the SFT stage significantly enhanced RL training efficiency.
The outcomes from our ablation study suggest valuable future research directions, particularly exploring curriculum learning strategies.
One potential avenue is examining curriculum design within a single domain vs capability, gradually increasing the complexity or difficulty to progressively enhance model competence.
Another intriguing direction involves investigating curriculum strategies that span multiple capabilities or domains—for instance, initially developing instruction-following capabilities before progressing to more complex reasoning tasks.
Understanding the efficacy and interaction of these curriculum strategies could significantly optimize training efficiency and ultimately enhance overall model performance. (Such kind of strategies have been employed by QwQ 32B, as illustrated in their technical report)
Rollout length scaling
As seen above as well as in many literatures (e.g. R1 paper), RL intrinsically encourage rollouts to become longer (unless specific length-control reward is used). However, we found that RL does not blindly increase rollout length - rather it tries to find an optimal length based on the given initial model. For example, the green graph below shows the length scaling using llama3.1 8B base model, while the purple graph uses the same llama3.1 8B model but warmed-up on ORZ data labeled by a CoT labeler (QwQ-32B-preview). The former model was not trained on CoT data at all, and tends to generate short responses from the start. In order to achieve higher math accuracy, RL encourages the model to output longer responses. On the other hand, the latter model, due to SFT effect, tends to generate very long responses from the beginning. RL actually suppressed generation length, while math accuracy also increases.
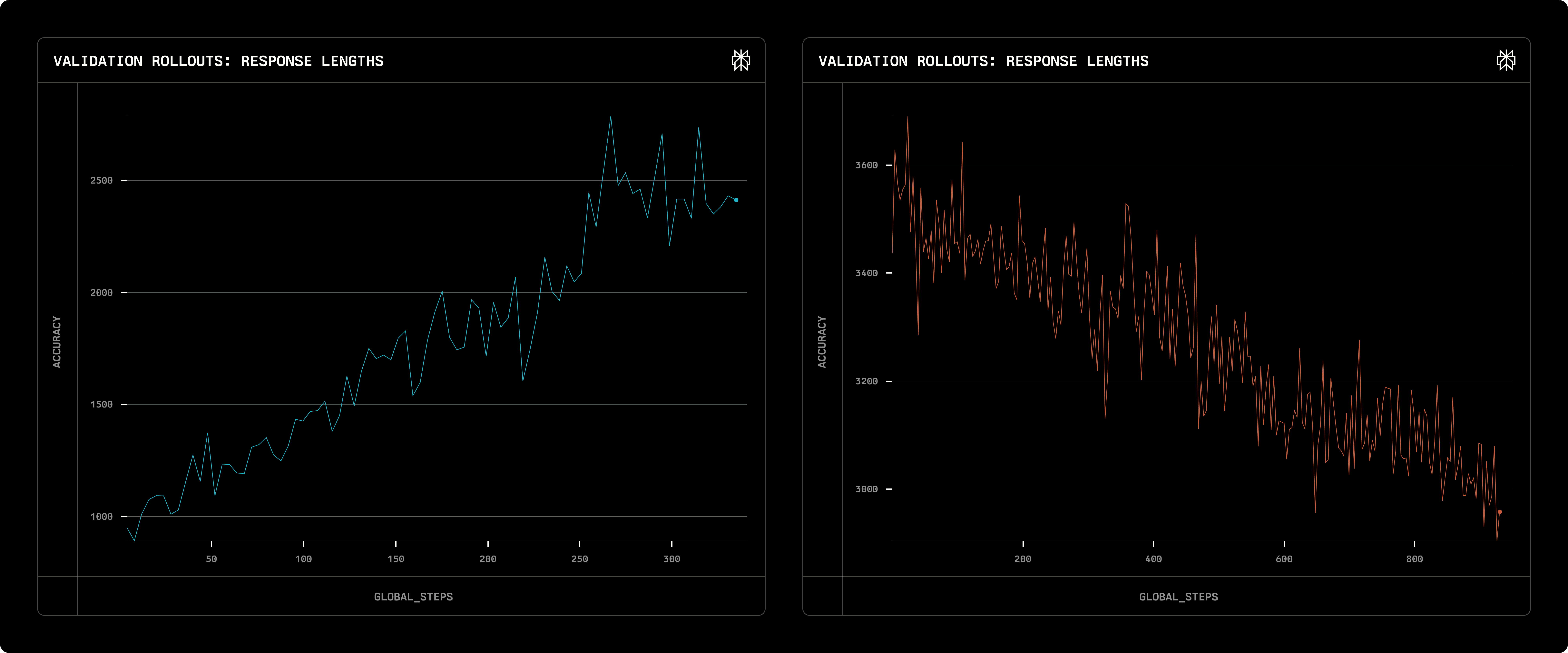
Rollout length scaling with different initial model: Llama 3.1 8B base (left) and SFT-warmed-up (right)
Limitations
The GRPO loss function and corresponding gradient update equations are provided below, highlighting potential biases introduced during gradient updates.
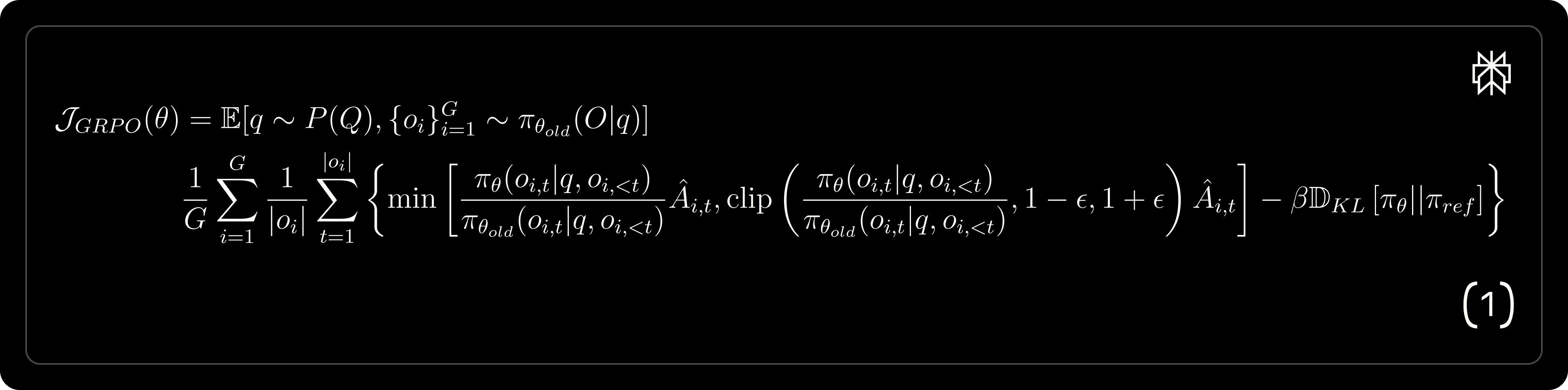

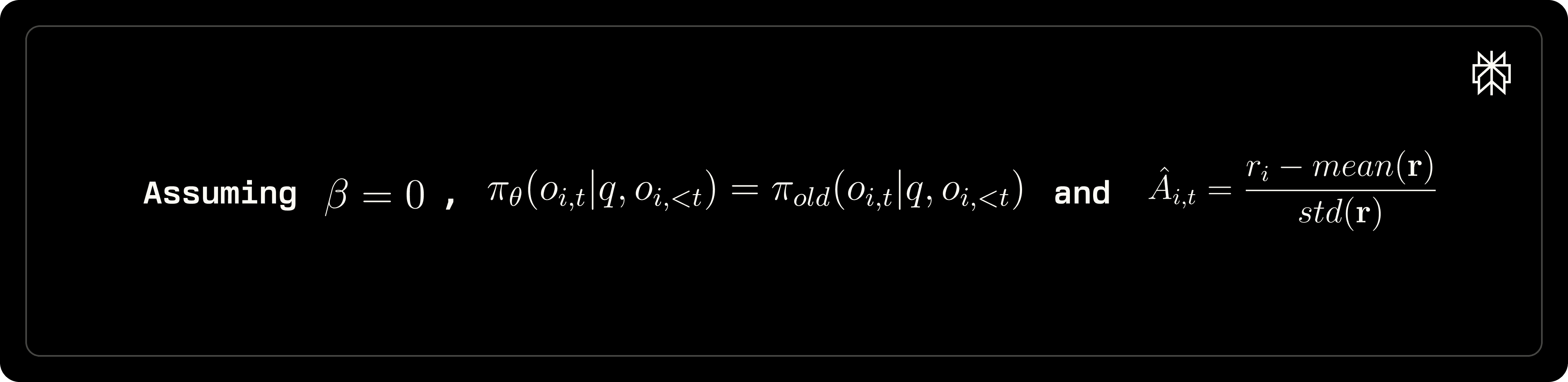
Advantage estimation biases
We note that the way advantage Âᵢ,ₜ is estimated can significantly affect model training. Specifically, normalizing by the standard deviation of group-level rewards introduces two key issues:
Vanishing Advantage for Uniform Responses. When all answers for a given query yield identical rewards, the resulted gradient becomes zero, causing the model to fail to update itself. A proposed solution is adjusting the reward calculation as follows:

Unequal Gradient Scaling Across Queries. Queries with low reward variance (typically easier questions) result in greater Âᵢ,ₜ , leading to disproportionately large advantage estimates and hence stronger gradient updates. In contrast, harder queries (with high variance) contribute less to learning. This introduces a bias in training favoring easy examples.
We plan to try these additional algorithm level modifications as our next steps.
Conclusion
In this work, we systematically explored reinforcement learning (RL) approaches for enhancing mathematical reasoning in large language models, focusing on the development and deployment of the GRPO algorithm within modern RL training infrastructures. Our experiments demonstrate that RL, particularly when initialized from models exposed to long chain-of-thought (CoT) reasoning via supervised fine-tuning, can substantially boost math reasoning accuracy and response quality. We identified that both the choice of base model and the diversity of supervised data critically impact RL efficiency and final performance. While our implementation addressed key technical challenges—such as rollout efficiency and log-probability alignment—issues like model collapse and advantage estimation bias remain open areas for further research. Overall, our findings provide a robust foundation for future work on curriculum strategies and algorithmic improvements, with the goal of advancing state-of-the-art math reasoning capabilities in language models.
Introduction and Motivation
Reinforcement Learning (RL) algorithms, especially proximal policy optimization (PPO) and Group Relative Policy Optimization (GRPO), have proven to be essential for improving model capabilities in reasoning related tasks. In this blog we’d like to share the learnings and decision reasonings we experienced when developing RL infra as well as training math-reasoning models with RL. For illustration purpose, the results we show below are based on smaller open source models, but most of them apply to larger models as well.
The goal of the RL model training exploration is two-folds: 1) share our lessons and learnings on how to train models to hit the state-of-the-art math reasoning performance. This equips the team with the right knowledge on data manipulation, data mixing recipes, training best practices, RL algorithm nuances, and general performance optimization experience. 2) Apply these learnings to real production use cases to improve Perplexity products.
A summary of the key findings:
Infrastructure: we’ve developed GRPO algorithm on torchtune library as well as the Nemo suite, with VLLM-based rollout integrated. Nemo will be our short term go-to infra for RL training, while we develop torchtune GRPO support, which will be our preferred infra in the longer-run, for self-contained maintenance (no external dependency) as well as simpler framework architecture.
Math dataset vested: gsm8k, math, NuminaMath, Open Reasoning Zero (ORZ), AIME series.
Math reasoning model training:
Data mixture of different difficulty levels matters
RL proves to be able to further improve large language models (LLMs) reasoning capability beyond supervised fine tuning (SFT)
The capability of base model matters a lot. In particular, long-CoT capability of the base model is important for further scaling with RL.
A good SFT starting checkpoint helps the above. Light SFT serves two purposes:
enable the RL base model to be comfortable with generating long-CoT responses. Without this ability, when RL forces the model to scale it’s response length, self-repeating collapse would happen.
teach some reasoning capability to the base model, enabling the RL process to start higher and learn faster from the start, compared to a model that only knows to generate long-CoT responses with weak reasoning capability.
Training infrastructure exploration
Despite several open source RL training frameworks being available, many of them do not fit our situation. Ideally we’d want the following properties:
Scales well with the large model sizes of our production models.
Good training speed optimizations.
Easy to implement new algorithms and maintain without too much external dependencies.
Simpler and extendable framework architecture design.
Ideally unify with SFT training framework.
Framework comparison
A comparison of the frameworks that we considered [the following table comparison was done in Feb 2025. Note that a lot of the missing algorithms were later implemented.]:
We chose Nemo Aligner as a short term option, and ruled out the rest due to the following reasons:
Nemo-Aligner: due to the most complete features already implemented, as well as partnership support from Nvidia, we chose this option as our short term focus. However, the complex setup with dependencies on multiple repos puts some overhead on maintenance.
torchtune: this is the SFT framework we use at Perplexity. The framework is elegantly designed and easy to extend in general. However, due to being fairly new, the framework lacks a lot of features to be added. We aim to shift to torchtune for RL in the long-run. Once we get Nemo-aligner to a good state, we will invest in maintaining an in-house version of torchtune with our own implementation of desired algorithms.
VeRL: although integrates both FSDP and more powerful Megatron-LM backend, the latter support is very limited due to the community’s demand being mostly on smaller models where FSDP is sufficient. FSDP generally has weaker support for tensor-parallelism, which is crucial for larger models, especially in RL training. However, VeRL quickly become a popular choice for the community, and has developed significantly in the recent months. Given its selling points on throughput optimizations, and multiple recent papers on reasoning/agentic model training based on this framework (e.g. [1], [2]), it’s worth revisiting this option in the near future.
openRLHF: popular in academic community. However, the DeepSpeed backend makes it less scalable to large models. We’ve ruled out this option.
Algorithm development and validation
In this section, we first provide a brief introduction to the GRPO algorithm and discuss the associated technical enhancements that contribute to its implementation complexity. Subsequently, we describe the infrastructure developed to address these challenges.
Comparison of PPO vs GRPO. ReferenBce: https://arxiv.org/abs/2402.03300
PPO is a popular RL algorithm widely used for fine-tuning LLMs due to its simplicity and effectiveness, as depicted above. However, PPO’s reliance on a separate value model introduces significant computational and memory overhead.
To address this limitation, GRPO modifies PPO by removing the separate value model and introducing group-based advantage calculation, as illustrated in figure above. Specifically, generates multiple candidate responses for each input question, computes their reward scores collectively, and determines advantages relative to these grouped outputs. While such innovation simplify certain aspect, they introduce new implementation complexities, such as efficiently generating multiple long-sequence rollouts.
Implementation details
Despite similar RL algorithms (PPO, Reinforce) already in-place in Nemo-Aligner, it’s surprisingly time consuming to make GRPO work properly for our case. A summary of improvements we did include:
GRPO algorithm implementation;
A more robust KL-divergence estimator (details);
Incorporate a format reward and enhance rules for mathematical accuracy (covering both numerical answers and symbolic ground-truth expressions);
Work with Nvidia support team to integrate VLLM-based rollout, which improved rollout efficiency by 30% and also fixed the buggy TensorRT-LLM infra that had log-probability mismatch (see next point)
Log-probability alignment with HF
Note: this effort was by-far the most time-consuming. In order to ensure code correctness, we adopt the following metric to verify the computed log-probabilities from Nemo-Aligner is correct:
where L is the length of a rollout, the first 𝓁𝑜𝑔𝓅ᵢ is the log-probability on the i-th token from Nemo-Aligner, and second 𝓁𝑜𝑔𝓅'ᵢ is the reference log-probability we get by manually running model.forward on a huggingface model directly. This metric needs to stay very close to 1.0. We went through several iterations of nemo model converter, repo update, and image rebuilding, to reduce the metric from 1e5 down to a normal range within [1, 1.05].
Multiple rounds of hyper-parameter searches to optimize for memory. Due to the fact that GRPO requires multiple samples per-prompt, as well as math reasoning rollouts are usually long, we often end up with cuda OOM issue. Hyper parameters, especially parallelism setup, needs to be carefully picked to ensure smooth training.
Minor issues with dataloader consumption early stopping, and tensor shape issues in corner cases.
Experiments
In this section, we present the experimental setup and results, building upon the previously described infrastructure.
Experimental setup
We evaluate the models on the MATH-500 dataset using the pass@1 metric defined as follows, and report results specifically for pass@1. During evaluation, we set the sampling temperature of 0.7 and a top-𝑝 value of 0.95 to generate k rollouts.
where 𝒫𝒾 denotes the correctness of the i-th response. The training and evaluation prompts are listed below, respectively. Specifically, we are not using system prompt, i.e. the following prompts are prepended into the user message.
# training prompt TRAINING_PROMPT = ( "A conversation between User and Assistant. The user asks a question, and the Assistant solves it. " "The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. " "The reasoning process and answer are enclosed within <think></think> and <answer></answer> tags, respectively, " "i.e., <think>reasoning process here</think> <answer>answer here</answer>. User: {question} Assistant: " )
# Evaluation prompt EVALUATION_PROMPT = ( "You will be given a problem.Please reason step by step, " "and put your final answer within \\boxed{}. " )
Additional experimental configurations are described below.
Model specifications:
We primarily experimented with dense Llama models, selecting our base models from the following two variants due to their suitable size and widespread adoption within the research community. These models serve as baseline references for reasoning performance in our subsequent experiments:
Llama 3.1 8B Instruct
Llama 3.1 8B Base
Dataset details:
The datasets collected and used in our experiments are as outlined below.
Sources | Size | Labeling Models | Difficulty | Usage |
|---|---|---|---|---|
Gsm8k | ~7k | QwQ 32B preview & R1 | Easy | Training |
MATH | ~7k | QwQ 32B preview & R1 | Medium | Training |
Orz (contains MATH) | ~57k | QwQ 32B preview & R1 | Hard | Training |
numinamath | ~250K (filtering) | None | Hard | Training |
MATH-500 | 500 | None | Medium | Evaluation |
Training procedure:
This subsection describes the specific training methods, specifically, the hyper-parameter selection, employed during GRPO-based fine-tuning.
Hyperparameters:
We used the GSM8K dataset for the training in this sub-section.
Learning Rate (LR) and KL coefficient:
We present accuracy results for various combinations of learning rates (LR) and KL coefficients below. (Note that some experimental runs terminated prematurely due to infrastructure-related errors, resulting in slight discrepancies in total training steps.)
Learning Rate/KL coefficient | 0.1 | 0.01 | 0.001 |
|---|---|---|---|
8e-8 | 0.426 | 0.434 | 0.422 |
1e-7 | 0.432 | 0.492 | 0.414 |
3e-7 | 0.470 | 0.488 | 0.470 |
5e-7 | 0.444 | 0.48 | 0.486 |
Analysis of these results indicates that a learning rate of 3e-7 consistently demonstrates stable performance across different KL settings, thus it was adopted for primary experiments. Moreover, experiments revealed improved outcomes with lower KL values, leading us to eliminate the KL term entirely in subsequent primary training runs. Higher learning rates such as 5e-7 and 8e-7 tended to accelerate early convergence, limiting the development of long-chain-of-thought (CoT) reasoning capabilities in late stage.
Temperature:
Temperatures tested: [0.7 (dark red), 0.8 (red), 1.0 (green), 1.1 (purple), 1.2 (blue), 1.3 (grey)]
The figures below are the training accuracy (left) vs the validation accuracy (right).
Temperature | 0.7 | 0.8 | 1 | 1.1 | 1.2 | 1.3 |
|---|---|---|---|---|---|---|
Validation | 0.502 | 0.48 | 0.452 | 0.442 | 0.184 | 0.082 |
Conclusions:
Based on the empirical results presented above, we select a temperature of 1.0 as the default setting, balancing convergence speed and overall accuracy.
Higher temperature settings (e.g., 1.2, 1.3) negatively impact convergence, resulting in instability and failure to achieve satisfactory performance.
Large temperature like, 1.2, 1.3 will make the model fail to converge
While lower temperature values (e.g., 0.7, 0.8 )facilitate rapid initial convergence, these settings typically lead to premature saturation, causing limited performance improvement on the validation set during later stages of training.
Reward models
In our preliminary experiments, we evaluated the following two rule-based reward models proposed in the DeepSeek paper:
Accuracy reward: This reward function assesses the correctness of the model's output by comparing the assistant's provided answers with predefined ground-truth solutions.
Format reward: This reward model encourages the language model to structure its responses in a predefined, consistent format. In our experiments, the desired format requires the LLMs to explicitly separate the reasoning process from the final answer by enclosing them within specific XML-like tags. More concretely, the expected format is shown in
TRAINING_PROMPTlisted above.
Results
Here are the training setup for our primary experiments:
LR = 3e-7, KL coefficient = 0, Temperature = 1, only Accuracy reward.
Main result
The figure below presents the primary results from this study, showcasing validation accuracy comparisons across three experimental conditions:
Validation on three RL setups: Left: train from SFT-warmed-up model; Mid: train from Llama 3.1 8B instruct; Right: train from Llama 3.1 8B Base
The three lines shown in the figure corresponding to the following setting
[Red] RL fine-tuning on the ORZ dataset initialized from the ORZ-supervised fine-tuned warm-up checkpoint (epoch 4). The SFT data is labeled by QwQ-32B-preview model, which is a CoT reasoning model.
[Green] RL fine-tuning on the ORZ dataset initialized from the vanilla Llama 3.1 8B instruct checkpoint.
[Blue] RL fine-tuning on the ORZ dataset initialized from the vanilla Llama 3.1 8B base checkpoint.
The results highlight two key findings:
RL significantly enhanced the models' mathematical reasoning capabilities, as evidenced by improvements in validation accuracy and increased generation lengths. (Notes: the accuracy of Llama 3.1 8B instruct and ORZ tuned model are about ~0.38 and ~0.60, respectively. The best RL result, Red line in the above graph, achieved 0.70 score on MATH500, which matches similar results in the literatures, e.g. [1], [2])
Prior exposure to long CoT reasoning data during supervised fine-tuning or the pre-training stage substantially accelerated the efficacy and efficiency of subsequent RL fine-tuning. From the curves above, it’s clear that the long-CoT exposure from SFT gets the Red line to start and plateau much higher than the other two. (Note: Contrary to the claims in some papers, our observations suggest that SFT enhances the efficiency of subsequent RL stages. While we hypothesize that SFT may also improve the upper-bound performance of the base model, we have not yet trained the model sufficiently to validate this hypothesis conclusively.)
Analysis of Observed Phenomena
During our experiments, we observed multiple noteworthy phenomena. Here we discuss these phenomena in detail.
Learning rate matters
We found that learning rate in GRPO generally controls 2 things: 1) how fast the learning picks up, and 2) how stable the convergence is. Smaller learning rate causes the learning to progress slower, which is expected. However, with a big learning rate, even though the learning curve climbs fast in early steps, it often leads to model collapse if continuously trained after convergence. In the graph below, the 3 lines corresponds to 3 different learning rates:
Purple:
8e-7,Green:
3e-7,Blue:
1e-7.
With lr=8e-7, the learning plateaus very early, but then causes model to collapse (and response length gets exploded) very fast. With lr=3e-7, learning reaches the same level near the end of 15k steps, and was stable, while with lr=1e-7, the learning is too slow that the training didn’t converge within 15k steps. (All three runs are using adam optimizer, learning rate schedule is constant).
Validation reward (i.e. accuracy) of three runs with different learning rate: Purple: 8e-7, Green: 3e-7; Blue: 1e-7
We will look further into why the reward curve collapses in the following Model Collapse section.
Model collapse
We define model collapse as the sudden deterioration in the generative capabilities of a model during RL training. It’s observed in two primary forms during our experiments: self-repetition collapse and end-of-sequence collapse.
Self-repetition collapse: This form of collapse emerged predominantly in experiments that incorporated a format reward. Initially intended to guide the model toward producing well-structured and interpretable outputs, the format reward required the model to organize its responses using distinct
<think></think>and<answer></answer>tags. However, while promoting structural clarity, we found that this reward signal inadvertently increased the likelihood of collapse via repetition.
Initially, we employed a relatively loose format reward—requiring at least one <think> block and one <answer> block—to encourage adoption of the desired response structure. In the following example, although the final reward converges well, the rollouts started to have severe repetition issue when training steps go beyond 110.
Validation format reward (left), math accuracy (mid) and rollout length (right) with loose format reward
A closer look at the rollouts reveals that after convergence, the model generates a normal thinking process (something without the <think> tags), then the correct answer, then a repetition of the format blocks with empty content (see example below).
<|start_header_id|>assistant<|end_header_id|><think> Let's denote the positive integer as n. When n is expressed in base 8, it forms the number $AB_8$, which can be written as $8A + B$. When n is expressed in base 6, it forms the number $BA_6$, which can be written as $6B + A$. Since both expressions represent the same number n, we can set them equal to each other: $8A + B = 6B + A$ Subtracting A from both sides gives: $7A = 5B$ Dividing both sides by 7 gives: $A=\frac{5}{7}B$ Since A and B are digits, they must be integers. The only way for A to be an integer is if B is a multiple of 7. The smallest possible value of B that satisfies this condition is B = 7. Substituting B = 7 into the equation A = (5/7)B gives: $A=\frac{5}{7} \times 7 = 5$ Now that we have the values of A and B, we can find the decimal value of n. We know that n in base 8 is represented as 57, so the decimal value of n is: $8 \times 5 + 7 = 40 + 7 = 47$ Therefore, the positive integer in decimal is $\boxed{47}$. </think> </answer> </think> </answer> </think> </answer> </think> </answer> </think>
To address this, we experimented with a stricter format reward requiring exactly one <think> block followed by one <answer> block. However, this adjustment exacerbated the problem: not only did repetition persist, but the accuracy of the answers also deteriorated [link].
Validation format reward (left), math accuracy (mid) and rollout length (right) with strict format reward
One illustrative example is attached below:
<|start_header_id|>assistant<|end_header_id|><think> To find the matrix $\mathbf{M}$, we can use the property of linear transformations that represents the transformation of vector $\mathbf{v}$ as $-4\mathbf{v}$. This means that the matrix $\mathbf{M}$ must be a scalar multiple of the identity matrix, where the scalar is $-4$. </think> <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </think> ........ <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </think> <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}}</answer>
Based on these observations, we initially hypothesized that the format reward itself was the primary cause of the collapse. To test this, we conducted follow-up experiments with the format reward entirely removed which leads us to the following end-of-sequence collapse.
End-of-sequence collapse: this collapse occurs when the model reaches the maximum allowed token generation limit, subsequently causing a performance breakdown.
This phenomenon likely results from ill-defined loss scenarios, where multiple outputs from a single input query uniformly receive identical rewards. This happens when all rollouts of a prompt are cut-off, causing the reward to all be 0, thus the advantage is also 0. Let’s take a further look at the reward curve collapsing example in the Learning Rate Matters section. In this case, KL coefficient is set to 0. For prompts whose rollouts are all cut-off, it’s impossible to get the policy away from this state, because policy gradient becomes 0 [see Eq 2 in Limitations section]. The math accuracy starts to decrease as more rollouts get cut-off, and then got stuck in this situation. In the following graphs, we can see a clear correlation between the cut-off rate and train rollout reward drop.
End-of-sequence collapse. Training reward collapse aligns with rollout cut-off
Note that the end-of-sequence collapse is also observed in Demystifying Long Chain-of-Thought Reasoning in LLMs, even with the KL-term added. Their paper proposed a reward shaping approach that tries to control the rollout sequence length. However, our experiments show that while reward shaping successfully suppressed the generation length (length collapse), it hindered model from learning the correct reasoning and answer, causing much lower math accuracy throughout training:
Validation accuracy and response length with reward shaping
In the Limitations section, we will propose new ways to handle this situation. Combining the previous self-repetition example and main results above, it seems with a based model that’s not exposed to long CoT reasoning answers, RL would cause the model to brokenly scale up response length and eventually collapse with repetition.
Base model capability
We conducted an ablation study to investigate the impact of SFT on subsequent RL performance. Models were first fine-tuned using datasets of varying difficulty levels—ORZ (difficult), MATH (medium), and GSM8K (easy)—followed by RL fine-tuning exclusively on the ORZ dataset.
Validation accuracy on different initial models
[Blue]: SFT on ORZ (difficulty: difficult) data then RL on ORZ
[Red]: SFT on MATH (difficulty: medium) data then RL on ORZ
[Green]: SFT on GSM8K (difficulty: easy) data then RL on ORZ
The results clearly indicated that employing a diverse mixture of difficulty levels in the SFT stage significantly enhanced RL training efficiency.
The outcomes from our ablation study suggest valuable future research directions, particularly exploring curriculum learning strategies.
One potential avenue is examining curriculum design within a single domain vs capability, gradually increasing the complexity or difficulty to progressively enhance model competence.
Another intriguing direction involves investigating curriculum strategies that span multiple capabilities or domains—for instance, initially developing instruction-following capabilities before progressing to more complex reasoning tasks.
Understanding the efficacy and interaction of these curriculum strategies could significantly optimize training efficiency and ultimately enhance overall model performance. (Such kind of strategies have been employed by QwQ 32B, as illustrated in their technical report)
Rollout length scaling
As seen above as well as in many literatures (e.g. R1 paper), RL intrinsically encourage rollouts to become longer (unless specific length-control reward is used). However, we found that RL does not blindly increase rollout length - rather it tries to find an optimal length based on the given initial model. For example, the green graph below shows the length scaling using llama3.1 8B base model, while the purple graph uses the same llama3.1 8B model but warmed-up on ORZ data labeled by a CoT labeler (QwQ-32B-preview). The former model was not trained on CoT data at all, and tends to generate short responses from the start. In order to achieve higher math accuracy, RL encourages the model to output longer responses. On the other hand, the latter model, due to SFT effect, tends to generate very long responses from the beginning. RL actually suppressed generation length, while math accuracy also increases.
Rollout length scaling with different initial model: Llama 3.1 8B base (left) and SFT-warmed-up (right)
Limitations
The GRPO loss function and corresponding gradient update equations are provided below, highlighting potential biases introduced during gradient updates.
Advantage estimation biases
We note that the way advantage Âᵢ,ₜ is estimated can significantly affect model training. Specifically, normalizing by the standard deviation of group-level rewards introduces two key issues:
Vanishing Advantage for Uniform Responses. When all answers for a given query yield identical rewards, the resulted gradient becomes zero, causing the model to fail to update itself. A proposed solution is adjusting the reward calculation as follows:
Unequal Gradient Scaling Across Queries. Queries with low reward variance (typically easier questions) result in greater Âᵢ,ₜ , leading to disproportionately large advantage estimates and hence stronger gradient updates. In contrast, harder queries (with high variance) contribute less to learning. This introduces a bias in training favoring easy examples.
We plan to try these additional algorithm level modifications as our next steps.
Conclusion
In this work, we systematically explored reinforcement learning (RL) approaches for enhancing mathematical reasoning in large language models, focusing on the development and deployment of the GRPO algorithm within modern RL training infrastructures. Our experiments demonstrate that RL, particularly when initialized from models exposed to long chain-of-thought (CoT) reasoning via supervised fine-tuning, can substantially boost math reasoning accuracy and response quality. We identified that both the choice of base model and the diversity of supervised data critically impact RL efficiency and final performance. While our implementation addressed key technical challenges—such as rollout efficiency and log-probability alignment—issues like model collapse and advantage estimation bias remain open areas for further research. Overall, our findings provide a robust foundation for future work on curriculum strategies and algorithmic improvements, with the goal of advancing state-of-the-art math reasoning capabilities in language models.
Introduction and Motivation
Reinforcement Learning (RL) algorithms, especially proximal policy optimization (PPO) and Group Relative Policy Optimization (GRPO), have proven to be essential for improving model capabilities in reasoning related tasks. In this blog we’d like to share the learnings and decision reasonings we experienced when developing RL infra as well as training math-reasoning models with RL. For illustration purpose, the results we show below are based on smaller open source models, but most of them apply to larger models as well.
The goal of the RL model training exploration is two-folds: 1) share our lessons and learnings on how to train models to hit the state-of-the-art math reasoning performance. This equips the team with the right knowledge on data manipulation, data mixing recipes, training best practices, RL algorithm nuances, and general performance optimization experience. 2) Apply these learnings to real production use cases to improve Perplexity products.
A summary of the key findings:
Infrastructure: we’ve developed GRPO algorithm on torchtune library as well as the Nemo suite, with VLLM-based rollout integrated. Nemo will be our short term go-to infra for RL training, while we develop torchtune GRPO support, which will be our preferred infra in the longer-run, for self-contained maintenance (no external dependency) as well as simpler framework architecture.
Math dataset vested: gsm8k, math, NuminaMath, Open Reasoning Zero (ORZ), AIME series.
Math reasoning model training:
Data mixture of different difficulty levels matters
RL proves to be able to further improve large language models (LLMs) reasoning capability beyond supervised fine tuning (SFT)
The capability of base model matters a lot. In particular, long-CoT capability of the base model is important for further scaling with RL.
A good SFT starting checkpoint helps the above. Light SFT serves two purposes:
enable the RL base model to be comfortable with generating long-CoT responses. Without this ability, when RL forces the model to scale it’s response length, self-repeating collapse would happen.
teach some reasoning capability to the base model, enabling the RL process to start higher and learn faster from the start, compared to a model that only knows to generate long-CoT responses with weak reasoning capability.
Training infrastructure exploration
Despite several open source RL training frameworks being available, many of them do not fit our situation. Ideally we’d want the following properties:
Scales well with the large model sizes of our production models.
Good training speed optimizations.
Easy to implement new algorithms and maintain without too much external dependencies.
Simpler and extendable framework architecture design.
Ideally unify with SFT training framework.
Framework comparison
A comparison of the frameworks that we considered [the following table comparison was done in Feb 2025. Note that a lot of the missing algorithms were later implemented.]:
We chose Nemo Aligner as a short term option, and ruled out the rest due to the following reasons:
Nemo-Aligner: due to the most complete features already implemented, as well as partnership support from Nvidia, we chose this option as our short term focus. However, the complex setup with dependencies on multiple repos puts some overhead on maintenance.
torchtune: this is the SFT framework we use at Perplexity. The framework is elegantly designed and easy to extend in general. However, due to being fairly new, the framework lacks a lot of features to be added. We aim to shift to torchtune for RL in the long-run. Once we get Nemo-aligner to a good state, we will invest in maintaining an in-house version of torchtune with our own implementation of desired algorithms.
VeRL: although integrates both FSDP and more powerful Megatron-LM backend, the latter support is very limited due to the community’s demand being mostly on smaller models where FSDP is sufficient. FSDP generally has weaker support for tensor-parallelism, which is crucial for larger models, especially in RL training. However, VeRL quickly become a popular choice for the community, and has developed significantly in the recent months. Given its selling points on throughput optimizations, and multiple recent papers on reasoning/agentic model training based on this framework (e.g. [1], [2]), it’s worth revisiting this option in the near future.
openRLHF: popular in academic community. However, the DeepSpeed backend makes it less scalable to large models. We’ve ruled out this option.
Algorithm development and validation
In this section, we first provide a brief introduction to the GRPO algorithm and discuss the associated technical enhancements that contribute to its implementation complexity. Subsequently, we describe the infrastructure developed to address these challenges.
Comparison of PPO vs GRPO. ReferenBce: https://arxiv.org/abs/2402.03300
PPO is a popular RL algorithm widely used for fine-tuning LLMs due to its simplicity and effectiveness, as depicted above. However, PPO’s reliance on a separate value model introduces significant computational and memory overhead.
To address this limitation, GRPO modifies PPO by removing the separate value model and introducing group-based advantage calculation, as illustrated in figure above. Specifically, generates multiple candidate responses for each input question, computes their reward scores collectively, and determines advantages relative to these grouped outputs. While such innovation simplify certain aspect, they introduce new implementation complexities, such as efficiently generating multiple long-sequence rollouts.
Implementation details
Despite similar RL algorithms (PPO, Reinforce) already in-place in Nemo-Aligner, it’s surprisingly time consuming to make GRPO work properly for our case. A summary of improvements we did include:
GRPO algorithm implementation;
A more robust KL-divergence estimator (details);
Incorporate a format reward and enhance rules for mathematical accuracy (covering both numerical answers and symbolic ground-truth expressions);
Work with Nvidia support team to integrate VLLM-based rollout, which improved rollout efficiency by 30% and also fixed the buggy TensorRT-LLM infra that had log-probability mismatch (see next point)
Log-probability alignment with HF
Note: this effort was by-far the most time-consuming. In order to ensure code correctness, we adopt the following metric to verify the computed log-probabilities from Nemo-Aligner is correct:
where L is the length of a rollout, the first 𝓁𝑜𝑔𝓅ᵢ is the log-probability on the i-th token from Nemo-Aligner, and second 𝓁𝑜𝑔𝓅'ᵢ is the reference log-probability we get by manually running model.forward on a huggingface model directly. This metric needs to stay very close to 1.0. We went through several iterations of nemo model converter, repo update, and image rebuilding, to reduce the metric from 1e5 down to a normal range within [1, 1.05].
Multiple rounds of hyper-parameter searches to optimize for memory. Due to the fact that GRPO requires multiple samples per-prompt, as well as math reasoning rollouts are usually long, we often end up with cuda OOM issue. Hyper parameters, especially parallelism setup, needs to be carefully picked to ensure smooth training.
Minor issues with dataloader consumption early stopping, and tensor shape issues in corner cases.
Experiments
In this section, we present the experimental setup and results, building upon the previously described infrastructure.
Experimental setup
We evaluate the models on the MATH-500 dataset using the pass@1 metric defined as follows, and report results specifically for pass@1. During evaluation, we set the sampling temperature of 0.7 and a top-𝑝 value of 0.95 to generate k rollouts.
where 𝒫𝒾 denotes the correctness of the i-th response. The training and evaluation prompts are listed below, respectively. Specifically, we are not using system prompt, i.e. the following prompts are prepended into the user message.
# training prompt TRAINING_PROMPT = ( "A conversation between User and Assistant. The user asks a question, and the Assistant solves it. " "The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. " "The reasoning process and answer are enclosed within <think></think> and <answer></answer> tags, respectively, " "i.e., <think>reasoning process here</think> <answer>answer here</answer>. User: {question} Assistant: " )
# Evaluation prompt EVALUATION_PROMPT = ( "You will be given a problem.Please reason step by step, " "and put your final answer within \\boxed{}. " )
Additional experimental configurations are described below.
Model specifications:
We primarily experimented with dense Llama models, selecting our base models from the following two variants due to their suitable size and widespread adoption within the research community. These models serve as baseline references for reasoning performance in our subsequent experiments:
Llama 3.1 8B Instruct
Llama 3.1 8B Base
Dataset details:
The datasets collected and used in our experiments are as outlined below.
Sources | Size | Labeling Models | Difficulty | Usage |
|---|---|---|---|---|
Gsm8k | ~7k | QwQ 32B preview & R1 | Easy | Training |
MATH | ~7k | QwQ 32B preview & R1 | Medium | Training |
Orz (contains MATH) | ~57k | QwQ 32B preview & R1 | Hard | Training |
numinamath | ~250K (filtering) | None | Hard | Training |
MATH-500 | 500 | None | Medium | Evaluation |
Training procedure:
This subsection describes the specific training methods, specifically, the hyper-parameter selection, employed during GRPO-based fine-tuning.
Hyperparameters:
We used the GSM8K dataset for the training in this sub-section.
Learning Rate (LR) and KL coefficient:
We present accuracy results for various combinations of learning rates (LR) and KL coefficients below. (Note that some experimental runs terminated prematurely due to infrastructure-related errors, resulting in slight discrepancies in total training steps.)
Learning Rate/KL coefficient | 0.1 | 0.01 | 0.001 |
|---|---|---|---|
8e-8 | 0.426 | 0.434 | 0.422 |
1e-7 | 0.432 | 0.492 | 0.414 |
3e-7 | 0.470 | 0.488 | 0.470 |
5e-7 | 0.444 | 0.48 | 0.486 |
Analysis of these results indicates that a learning rate of 3e-7 consistently demonstrates stable performance across different KL settings, thus it was adopted for primary experiments. Moreover, experiments revealed improved outcomes with lower KL values, leading us to eliminate the KL term entirely in subsequent primary training runs. Higher learning rates such as 5e-7 and 8e-7 tended to accelerate early convergence, limiting the development of long-chain-of-thought (CoT) reasoning capabilities in late stage.
Temperature:
Temperatures tested: [0.7 (dark red), 0.8 (red), 1.0 (green), 1.1 (purple), 1.2 (blue), 1.3 (grey)]
The figures below are the training accuracy (left) vs the validation accuracy (right).
Temperature | 0.7 | 0.8 | 1 | 1.1 | 1.2 | 1.3 |
|---|---|---|---|---|---|---|
Validation | 0.502 | 0.48 | 0.452 | 0.442 | 0.184 | 0.082 |
Conclusions:
Based on the empirical results presented above, we select a temperature of 1.0 as the default setting, balancing convergence speed and overall accuracy.
Higher temperature settings (e.g., 1.2, 1.3) negatively impact convergence, resulting in instability and failure to achieve satisfactory performance.
Large temperature like, 1.2, 1.3 will make the model fail to converge
While lower temperature values (e.g., 0.7, 0.8 )facilitate rapid initial convergence, these settings typically lead to premature saturation, causing limited performance improvement on the validation set during later stages of training.
Reward models
In our preliminary experiments, we evaluated the following two rule-based reward models proposed in the DeepSeek paper:
Accuracy reward: This reward function assesses the correctness of the model's output by comparing the assistant's provided answers with predefined ground-truth solutions.
Format reward: This reward model encourages the language model to structure its responses in a predefined, consistent format. In our experiments, the desired format requires the LLMs to explicitly separate the reasoning process from the final answer by enclosing them within specific XML-like tags. More concretely, the expected format is shown in
TRAINING_PROMPTlisted above.
Results
Here are the training setup for our primary experiments:
LR = 3e-7, KL coefficient = 0, Temperature = 1, only Accuracy reward.
Main result
The figure below presents the primary results from this study, showcasing validation accuracy comparisons across three experimental conditions:
Validation on three RL setups: Left: train from SFT-warmed-up model; Mid: train from Llama 3.1 8B instruct; Right: train from Llama 3.1 8B Base
The three lines shown in the figure corresponding to the following setting
[Red] RL fine-tuning on the ORZ dataset initialized from the ORZ-supervised fine-tuned warm-up checkpoint (epoch 4). The SFT data is labeled by QwQ-32B-preview model, which is a CoT reasoning model.
[Green] RL fine-tuning on the ORZ dataset initialized from the vanilla Llama 3.1 8B instruct checkpoint.
[Blue] RL fine-tuning on the ORZ dataset initialized from the vanilla Llama 3.1 8B base checkpoint.
The results highlight two key findings:
RL significantly enhanced the models' mathematical reasoning capabilities, as evidenced by improvements in validation accuracy and increased generation lengths. (Notes: the accuracy of Llama 3.1 8B instruct and ORZ tuned model are about ~0.38 and ~0.60, respectively. The best RL result, Red line in the above graph, achieved 0.70 score on MATH500, which matches similar results in the literatures, e.g. [1], [2])
Prior exposure to long CoT reasoning data during supervised fine-tuning or the pre-training stage substantially accelerated the efficacy and efficiency of subsequent RL fine-tuning. From the curves above, it’s clear that the long-CoT exposure from SFT gets the Red line to start and plateau much higher than the other two. (Note: Contrary to the claims in some papers, our observations suggest that SFT enhances the efficiency of subsequent RL stages. While we hypothesize that SFT may also improve the upper-bound performance of the base model, we have not yet trained the model sufficiently to validate this hypothesis conclusively.)
Analysis of Observed Phenomena
During our experiments, we observed multiple noteworthy phenomena. Here we discuss these phenomena in detail.
Learning rate matters
We found that learning rate in GRPO generally controls 2 things: 1) how fast the learning picks up, and 2) how stable the convergence is. Smaller learning rate causes the learning to progress slower, which is expected. However, with a big learning rate, even though the learning curve climbs fast in early steps, it often leads to model collapse if continuously trained after convergence. In the graph below, the 3 lines corresponds to 3 different learning rates:
Purple:
8e-7,Green:
3e-7,Blue:
1e-7.
With lr=8e-7, the learning plateaus very early, but then causes model to collapse (and response length gets exploded) very fast. With lr=3e-7, learning reaches the same level near the end of 15k steps, and was stable, while with lr=1e-7, the learning is too slow that the training didn’t converge within 15k steps. (All three runs are using adam optimizer, learning rate schedule is constant).
Validation reward (i.e. accuracy) of three runs with different learning rate: Purple: 8e-7, Green: 3e-7; Blue: 1e-7
We will look further into why the reward curve collapses in the following Model Collapse section.
Model collapse
We define model collapse as the sudden deterioration in the generative capabilities of a model during RL training. It’s observed in two primary forms during our experiments: self-repetition collapse and end-of-sequence collapse.
Self-repetition collapse: This form of collapse emerged predominantly in experiments that incorporated a format reward. Initially intended to guide the model toward producing well-structured and interpretable outputs, the format reward required the model to organize its responses using distinct
<think></think>and<answer></answer>tags. However, while promoting structural clarity, we found that this reward signal inadvertently increased the likelihood of collapse via repetition.
Initially, we employed a relatively loose format reward—requiring at least one <think> block and one <answer> block—to encourage adoption of the desired response structure. In the following example, although the final reward converges well, the rollouts started to have severe repetition issue when training steps go beyond 110.
Validation format reward (left), math accuracy (mid) and rollout length (right) with loose format reward
A closer look at the rollouts reveals that after convergence, the model generates a normal thinking process (something without the <think> tags), then the correct answer, then a repetition of the format blocks with empty content (see example below).
<|start_header_id|>assistant<|end_header_id|><think> Let's denote the positive integer as n. When n is expressed in base 8, it forms the number $AB_8$, which can be written as $8A + B$. When n is expressed in base 6, it forms the number $BA_6$, which can be written as $6B + A$. Since both expressions represent the same number n, we can set them equal to each other: $8A + B = 6B + A$ Subtracting A from both sides gives: $7A = 5B$ Dividing both sides by 7 gives: $A=\frac{5}{7}B$ Since A and B are digits, they must be integers. The only way for A to be an integer is if B is a multiple of 7. The smallest possible value of B that satisfies this condition is B = 7. Substituting B = 7 into the equation A = (5/7)B gives: $A=\frac{5}{7} \times 7 = 5$ Now that we have the values of A and B, we can find the decimal value of n. We know that n in base 8 is represented as 57, so the decimal value of n is: $8 \times 5 + 7 = 40 + 7 = 47$ Therefore, the positive integer in decimal is $\boxed{47}$. </think> </answer> </think> </answer> </think> </answer> </think> </answer> </think>
To address this, we experimented with a stricter format reward requiring exactly one <think> block followed by one <answer> block. However, this adjustment exacerbated the problem: not only did repetition persist, but the accuracy of the answers also deteriorated [link].
Validation format reward (left), math accuracy (mid) and rollout length (right) with strict format reward
One illustrative example is attached below:
<|start_header_id|>assistant<|end_header_id|><think> To find the matrix $\mathbf{M}$, we can use the property of linear transformations that represents the transformation of vector $\mathbf{v}$ as $-4\mathbf{v}$. This means that the matrix $\mathbf{M}$ must be a scalar multiple of the identity matrix, where the scalar is $-4$. </think> <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </think> ........ <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </think> <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}}</answer>
Based on these observations, we initially hypothesized that the format reward itself was the primary cause of the collapse. To test this, we conducted follow-up experiments with the format reward entirely removed which leads us to the following end-of-sequence collapse.
End-of-sequence collapse: this collapse occurs when the model reaches the maximum allowed token generation limit, subsequently causing a performance breakdown.
This phenomenon likely results from ill-defined loss scenarios, where multiple outputs from a single input query uniformly receive identical rewards. This happens when all rollouts of a prompt are cut-off, causing the reward to all be 0, thus the advantage is also 0. Let’s take a further look at the reward curve collapsing example in the Learning Rate Matters section. In this case, KL coefficient is set to 0. For prompts whose rollouts are all cut-off, it’s impossible to get the policy away from this state, because policy gradient becomes 0 [see Eq 2 in Limitations section]. The math accuracy starts to decrease as more rollouts get cut-off, and then got stuck in this situation. In the following graphs, we can see a clear correlation between the cut-off rate and train rollout reward drop.
End-of-sequence collapse. Training reward collapse aligns with rollout cut-off
Note that the end-of-sequence collapse is also observed in Demystifying Long Chain-of-Thought Reasoning in LLMs, even with the KL-term added. Their paper proposed a reward shaping approach that tries to control the rollout sequence length. However, our experiments show that while reward shaping successfully suppressed the generation length (length collapse), it hindered model from learning the correct reasoning and answer, causing much lower math accuracy throughout training:
Validation accuracy and response length with reward shaping
In the Limitations section, we will propose new ways to handle this situation. Combining the previous self-repetition example and main results above, it seems with a based model that’s not exposed to long CoT reasoning answers, RL would cause the model to brokenly scale up response length and eventually collapse with repetition.
Base model capability
We conducted an ablation study to investigate the impact of SFT on subsequent RL performance. Models were first fine-tuned using datasets of varying difficulty levels—ORZ (difficult), MATH (medium), and GSM8K (easy)—followed by RL fine-tuning exclusively on the ORZ dataset.
Validation accuracy on different initial models
[Blue]: SFT on ORZ (difficulty: difficult) data then RL on ORZ
[Red]: SFT on MATH (difficulty: medium) data then RL on ORZ
[Green]: SFT on GSM8K (difficulty: easy) data then RL on ORZ
The results clearly indicated that employing a diverse mixture of difficulty levels in the SFT stage significantly enhanced RL training efficiency.
The outcomes from our ablation study suggest valuable future research directions, particularly exploring curriculum learning strategies.
One potential avenue is examining curriculum design within a single domain vs capability, gradually increasing the complexity or difficulty to progressively enhance model competence.
Another intriguing direction involves investigating curriculum strategies that span multiple capabilities or domains—for instance, initially developing instruction-following capabilities before progressing to more complex reasoning tasks.
Understanding the efficacy and interaction of these curriculum strategies could significantly optimize training efficiency and ultimately enhance overall model performance. (Such kind of strategies have been employed by QwQ 32B, as illustrated in their technical report)
Rollout length scaling
As seen above as well as in many literatures (e.g. R1 paper), RL intrinsically encourage rollouts to become longer (unless specific length-control reward is used). However, we found that RL does not blindly increase rollout length - rather it tries to find an optimal length based on the given initial model. For example, the green graph below shows the length scaling using llama3.1 8B base model, while the purple graph uses the same llama3.1 8B model but warmed-up on ORZ data labeled by a CoT labeler (QwQ-32B-preview). The former model was not trained on CoT data at all, and tends to generate short responses from the start. In order to achieve higher math accuracy, RL encourages the model to output longer responses. On the other hand, the latter model, due to SFT effect, tends to generate very long responses from the beginning. RL actually suppressed generation length, while math accuracy also increases.
Rollout length scaling with different initial model: Llama 3.1 8B base (left) and SFT-warmed-up (right)
Limitations
The GRPO loss function and corresponding gradient update equations are provided below, highlighting potential biases introduced during gradient updates.
Advantage estimation biases
We note that the way advantage Âᵢ,ₜ is estimated can significantly affect model training. Specifically, normalizing by the standard deviation of group-level rewards introduces two key issues:
Vanishing Advantage for Uniform Responses. When all answers for a given query yield identical rewards, the resulted gradient becomes zero, causing the model to fail to update itself. A proposed solution is adjusting the reward calculation as follows:
Unequal Gradient Scaling Across Queries. Queries with low reward variance (typically easier questions) result in greater Âᵢ,ₜ , leading to disproportionately large advantage estimates and hence stronger gradient updates. In contrast, harder queries (with high variance) contribute less to learning. This introduces a bias in training favoring easy examples.
We plan to try these additional algorithm level modifications as our next steps.
Conclusion
In this work, we systematically explored reinforcement learning (RL) approaches for enhancing mathematical reasoning in large language models, focusing on the development and deployment of the GRPO algorithm within modern RL training infrastructures. Our experiments demonstrate that RL, particularly when initialized from models exposed to long chain-of-thought (CoT) reasoning via supervised fine-tuning, can substantially boost math reasoning accuracy and response quality. We identified that both the choice of base model and the diversity of supervised data critically impact RL efficiency and final performance. While our implementation addressed key technical challenges—such as rollout efficiency and log-probability alignment—issues like model collapse and advantage estimation bias remain open areas for further research. Overall, our findings provide a robust foundation for future work on curriculum strategies and algorithmic improvements, with the goal of advancing state-of-the-art math reasoning capabilities in language models.