
Search API: Better Extraction, Dynamic Benchmarks

In September, we published a technical overview of the Perplexity Search API architecture and released search_evals, our open-source evaluation framework for benchmarking search APIs in agentic workflows. Since then, the most significant investment has been in snippet quality, optimized along two dimensions: relevance and size. Returning the right content in the right amount directly determines downstream answer accuracy and token efficiency. The work to get there involved building new systems for extraction, span-level labeling, and evaluation, most notably a span-labeling pipeline that identifies which segments of a source document are responsive to a given query.
Evaluating snippets at the span level
To improve snippets systematically, we engineered a new evaluation system. For a given query and document, the system identifies and labels spans within the document by their relation to the query: "vital" spans that must be included in the snippet, various classes of "irrelevant" spans that should be excluded, duplicates, and other categories. This span-level labeling allows us to evaluate snippet quality with a level of precision that was not previously possible, measuring both what was correctly included and what was correctly omitted.
In practice, these improvements let us generate smaller snippets that are more relevant to the query. Our self-improving content understanding pipeline now handles a broader range of structured data formats, including tables, nested lists, and dynamically rendered content that earlier rulesets failed to parse reliably.
These improvements emerged from our own production systems. As our internal research drove snippet relevance and sizing forward, internal evaluations revealed that smaller content budgets actually produced more accurate results after a series of quality improvements. We made some modifications to our default configurations to reflect our findings, reducing response payload size and latency while delivering more useful content per result. For developers, smaller, more relevant snippets translate directly to lower token costs and better context management for downstream LLMs.
SEAL: benchmarking time-sensitive retrieval
The SEAL benchmark tests whether a retrieval system can answer questions whose correct response changes over time. Answering reliably requires real-time index freshness, smarter snippet extraction from various continuously updated data sources, and parsing that can identify the current value rather than a historical one.
When we ran search_evals against the February 22 SEAL release using Claude Sonnet 4.5, Perplexity scores increased while other providers declined on SEAL-Hard:
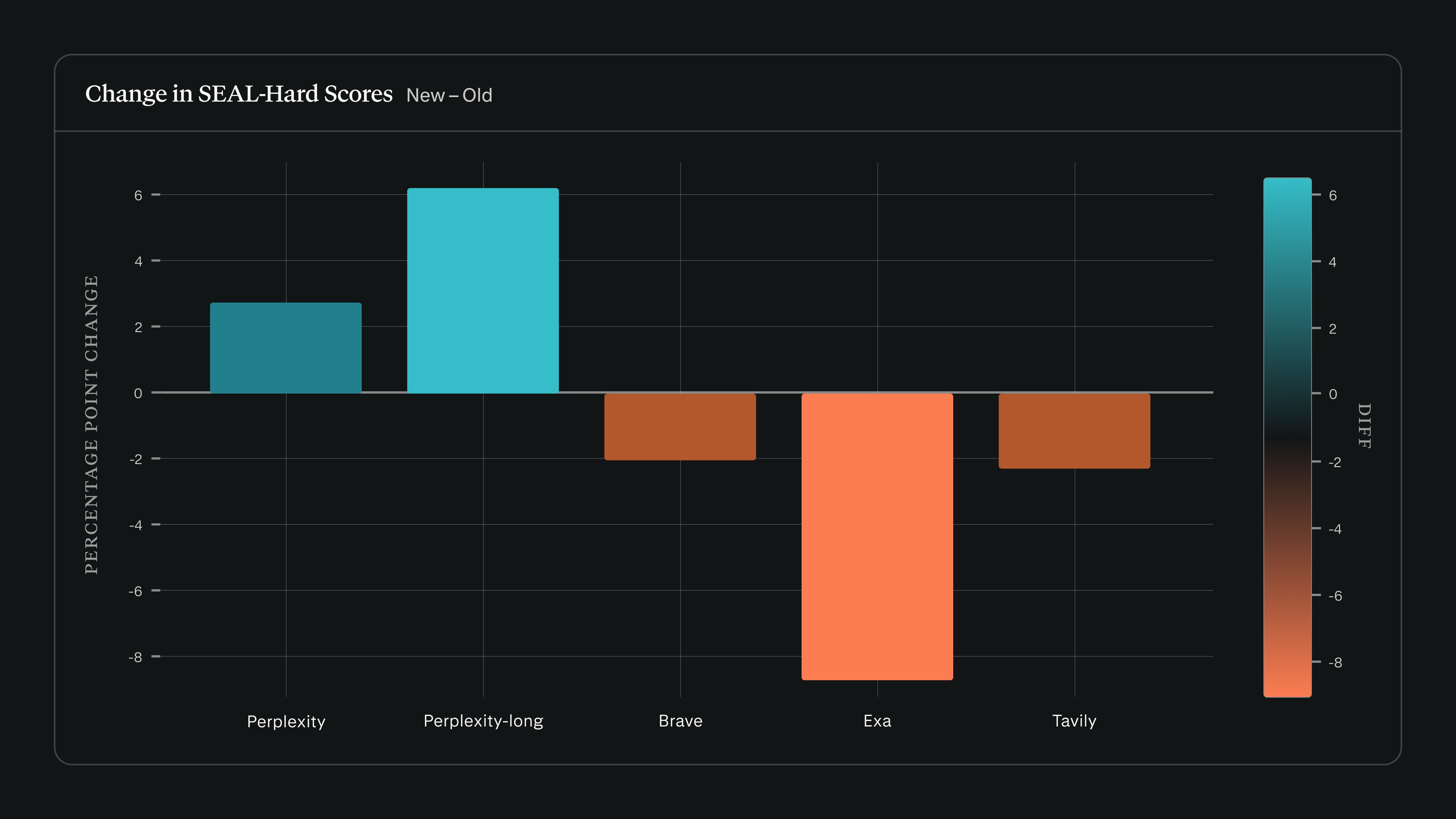
We have extended our search_evals framework to include SEAL alongside the benchmarks reported in our September post. Updated results and methodology are available in the updated repository on GitHub.
Multi-query support
The API now supports up to 5 queries in a single request. Results are returned grouped per query in the same order they were submitted. This reduces round trips for applications that need to issue related searches in parallel, such as agents that decompose a complex question into multiple retrieval sub-tasks.
Expanded filtering
In addition to domain filtering (allowlist and denylist, up to 20 domains) and recency filtering, the API now supports language filtering by ISO 639-1 code and regional search by ISO country code. These can be combined to scope results precisely, for example restricting to English-language results from German domains.
SDK and availability
The Python SDK (pip install perplexityai) now provides native support for Search API alongside Agent API and Sonar API.
Full documentation is at docs.perplexity.ai