


Written by
AI Team
Published on
Aug 25, 2023
Perplexity is excited to announce a major update to Copilot, our interactive research assistant feature, thanks to OpenAI's GPT-3.5 fine-tuning API. This update brings significant improvements in speed, cost-effectiveness, and overall performance, allowing Copilot to engage with our users faster while maintaining the high quality that Perplexity is known for.
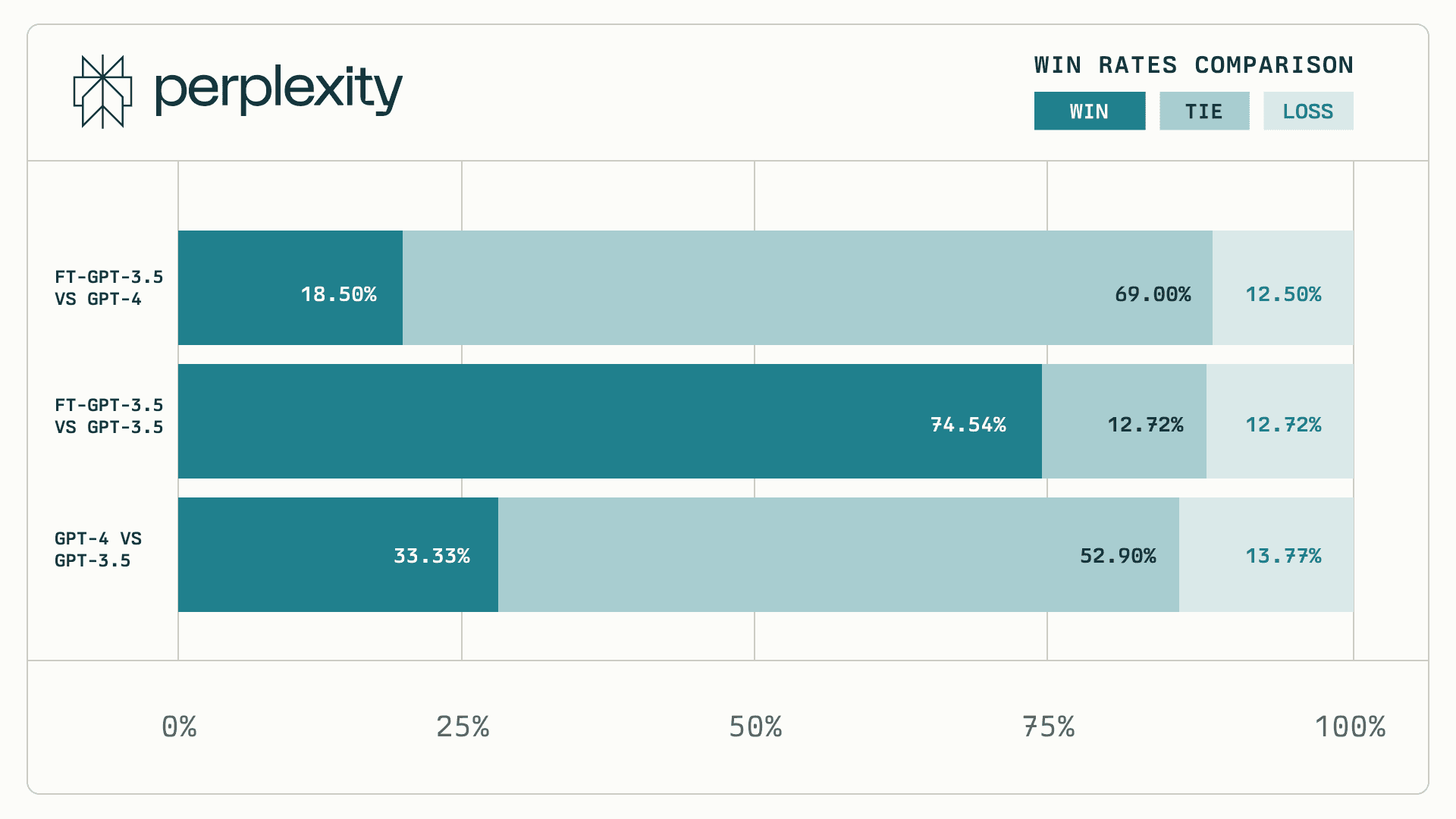
Performance Parity with GPT-4
We have fine-tuned our GPT-3.5 model to achieve performance that ties with the GPT-4-based model in human ranking on our specific tasks. But this upgrade isn't just about speed. We have prioritized delivering precise and accurate responses to complex queries, ensuring that customers receive the best of Copilot on Perplexity at their fingertips.
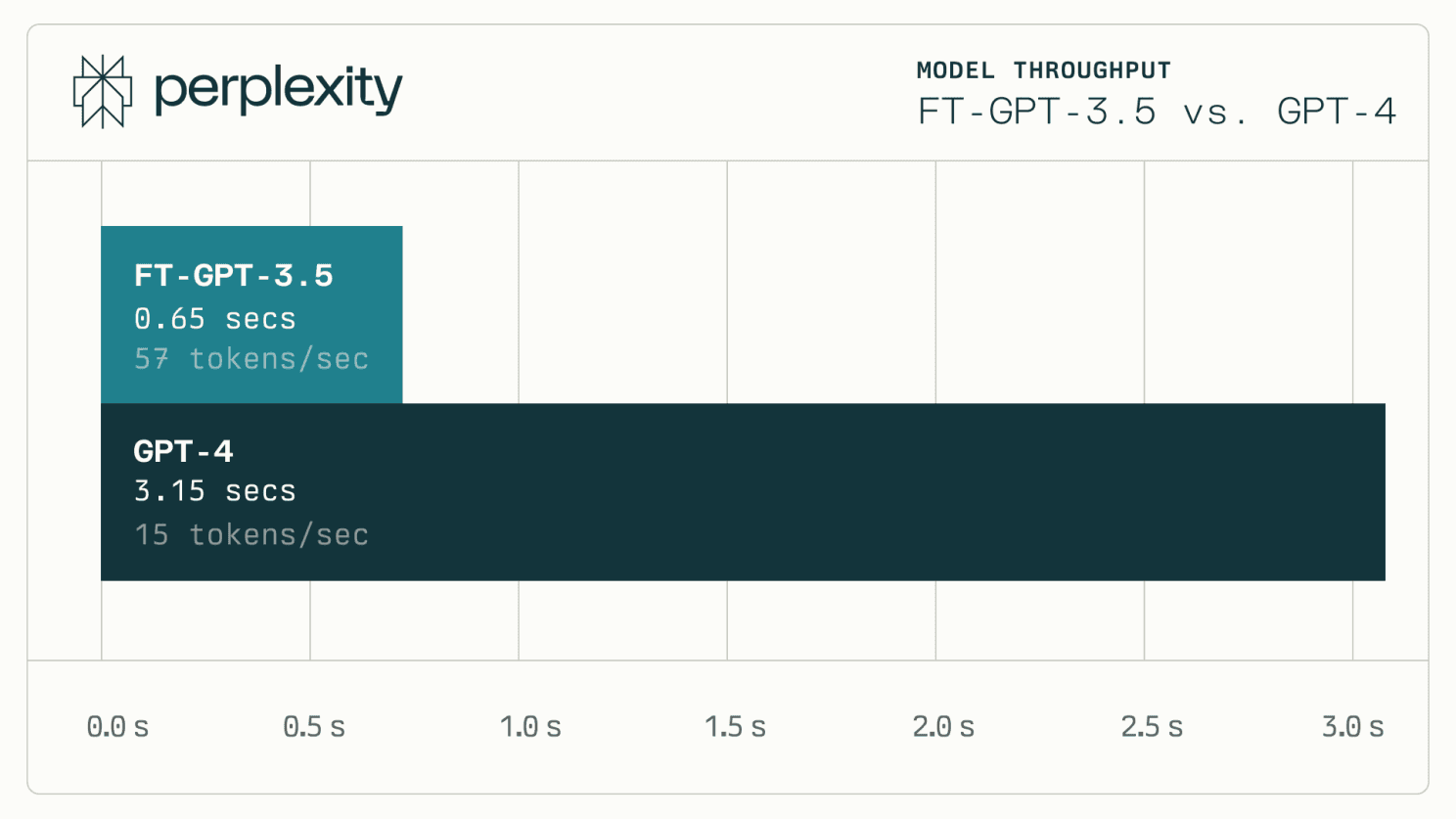
4-5x Latency Reduction
The new update has allowed us to reduce model latency by 4-5 times, serving results on average in just 0.65 seconds as compared to the previous 3.15 seconds. This speedup is noticeable when Copilot prompts users for input. In a world where every second counts, we believe in making each one productive and efficient.
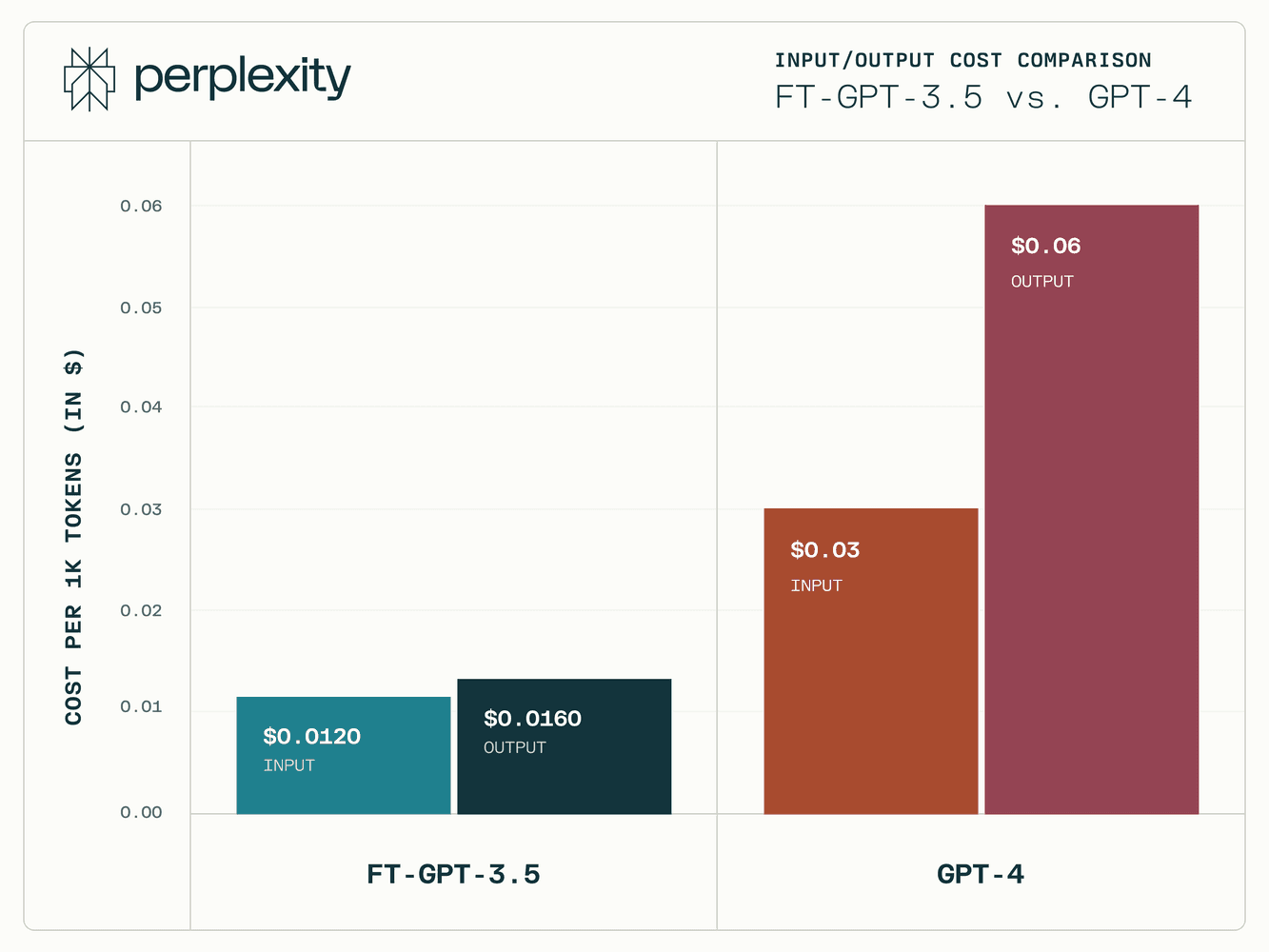
Cost Efficiency
Transitioning to the fine-tuned GPT-3.5 model has brought about a substantial reduction in inference costs. This cost-saving measure not only reflects our commitment to efficiency but also enables us to invest further in enhancing the Copilot experience on Perplexity. By reducing operational costs, we can focus on innovation and continual improvement.
Experience the Difference with Copilot on Perplexity
These updates have been achieved in a matter of days, demonstrating the power and flexibility of OpenAI's GPT-3.5 fine-tuning API. This collaboration paves the way for ongoing improvements to our models going forward.
Whether you're a researcher, student, or simply curious, Copilot on Perplexity is here to guide you on your path to understanding.
